4. 確率モデル#
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import pandas as pd
import scipy as sp
from scipy.stats import uniform, bernoulli, binom, norm, poisson, expon
# 日本語フォントの設定(Mac:'Hiragino Sans', Windows:'MS Gothic')
plt.rcParams['font.family'] = 'MS Gothic'
確率モデルとは,数理モデルの変数が確率変数となっているモデルであり,自然現象から社会現象まで様々な現象の記述に用いられる. 例えば,コイン投げは,表と裏が一定の確率で出現するという数理モデルで記述できる. また,株価の変動は,毎時刻ごとに株価の上がり幅と下がり幅が確率的に決まるようなモデル(ランダムウォーク)によって記述される. 本章では,確率モデルのシミュレーションで必要な乱数の生成,確率モデルにおいて重要となる大数の法則と中心極限定理,そしてランダムウォークの例であるマルコフ連鎖について取り上げる.
4.1. 乱数の生成#
ある数列が与えられたとき,数の並び方に規則性や周期性がない場合,この数列の各要素を乱数と呼ぶ. 乱数を生成するにはいくつかの方法がある. 例えば,サイコロを振って出た目を記録するだけでも,1〜6の数値からなる乱数を生成することができる. また,カオスや量子力学などの物理現象を利用した乱数は物理乱数と呼ばれ,規則性や周期性がない真の乱数として研究されている.
一方,コンピュータ上でアルゴリズムにしたがって乱数を生成する方法もある. このように生成された乱数は疑似乱数と呼ばれる. 疑似乱数はアルゴリズム次第で十分にランダムに見える値を高速に生成することができるため,シミュレーションにおいて役立つ. 一方,疑似乱数はアルゴリズムが分かれば値を予測することができてしまう,ある種の周期性が現れてしまう,などの欠点があるため,これを解決するための様々なアルゴリズムが提案されている.
4.1.1. 一様乱数#
乱数の中で最も基本的なものは,ある範囲の値が同じ確率で出現する一様乱数である. 一様乱数は,一様分布に従う確率変数の実現値と捉えることができ,様々な確率モデルの構築に用いられる. また,任意の確率分布に従う乱数を生成するためにも不可欠である.
線形合同法#
一様乱数を生成するアルゴリズムの中で,最も基本的なものが線形合同法である. 線形合同法にはいくつかの問題があるため,精度が求められる大規模なシミュレーションには使われないが,手軽に乱数を生成したりアルゴリズムの基礎を理解したりする上では有用である. 線形合同法のアルゴリズムは以下のように与えられる:
線形合同法のアルゴリズム
以下の大小関係を満たすように整数 \( a, b, M \) を決める:
\[\begin{split} 0 < a < M\\ 0 \leq b < M \end{split}\]乱数列の初期値 \( x_0 \) を決める(乱数のシードと呼ぶ).
以下の漸化式によって乱数列 \( \{u_n\} \) を生成する:
\[ u_{n+1} = (au_{n} + b) \% M \]ここで,\( \% \) は余りを求める演算子を表す.
以上のアルゴリズムを用いると,\( 0 \) 以上 \( M-1 \) 以下の一様乱数列が得られる. 線形合同法によって得られた一様乱数には実用的な問題が多く,例えば\( M \) が偶数の場合には偶数と奇数が交互に出現してしまう. また,同じ初期値(シード)からは同じ乱数列が得られるので,乱数列が必ず周期を持ってしまう. 特に,\( a, b, M \) がいくつかの条件を満たすと,最大周期が \( M \) となることが知られているため[5],良い乱数を生成するためには \( M \) を大きく取る必要がある. 例えば,\( M=2^{32},\ a=1664525,\ b=1013904223 \) の場合には,最大周期が \( 2^{32} \) となることが知られている.
Pythonでの実装
まず,アルゴリズムに従って素朴に実装すると以下のようになる.
# 線形合同法で100個の一様乱数を生成する
a, b, M = 1664525, 1013904223, 2**32
U = [0] # 初期値
for i in range(100):
u = (a * U[i] + b) % M
U.append(u)
print(np.array(U))
[ 0 1013904223 1196435762 3519870697 2868466484 1649599747
2670642822 1476291629 2748932008 2180890343 2498801434 3421909937
3167820124 2636375307 3801544430 28987765 2210837584 3039689583
1338634754 1649346937 2768872580 2254235155 2326606934 1719328701
1061592568 53332215 1140036074 4224358465 2629538988 1946028059
573775550 1473591045 95141024 1592739711 1618554578 4257218569
2685635028 2617994019 740185638 4194465613 2426187848 967350023
366635194 2557108433 3503432700 353185579 706247310 408928405
1855199472 1263785871 2223693730 594074265 684458788 3868161075
1929325558 166605533 2640352920 1798252823 2071081866 171871585
2087307084 698505787 3647212126 634580517 1956956480 2017242015
1181484146 1221761321 3441954932 962199875 571258310 3352760941
3763818728 1371701031 1288172122 2012225009 3960962716 4082010443
1249037870 3840393141 3947023760 3754607535 2143919426 1774599097
1818014148 136057427 2672030614 798365181 2575687480 732141879
2569577770 1449661057 3853535724 1541586011 2732705278 3432461637
320021984 2287935423 697346578 2555167305 2262755092]
次に,\( x_{\mathrm{min}} \) 以上 \( x_{\mathrm{max}} \) 以下の一様乱数を生成する汎用的な関数を作成する.
# 線形合同法により[0, 1)の一様乱数を生成する
def generagte_rand_u(seed=1, size=100, umin=0, umax=1):
a, b, M = 1664525, 1013904223, 2**32
U = [seed] # 初期値
for i in range(size-1):
u = (a * U[i] + b) % M
U.append(u)
U = np.array(U) # numpy配列に変換
# [umin, umax)の範囲に変換して返す
return umin + (umax - umin) * U / M
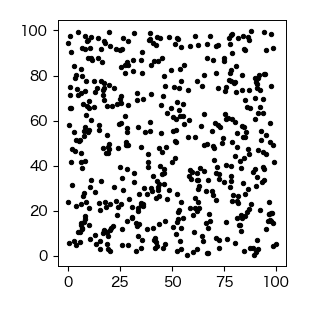
U = generagte_rand_u(seed=10, size=1000, umin=0, umax=100)
# 乱数列の相関を調べる
U2 = U.reshape(-1, 2)
fig, ax = plt.subplots(figsize=(3, 3))
ax.scatter(U2[:, 0], U2[:, 1], s=10);
より性能の良い一様乱数生成アルゴリズム#
線形合同法は,周期性の問題などがあるため,実用的にはより性能の良いアルゴリズムが用いられる. 例えば,NumpyやSciPyでは,高速で長い周期を持つ一様乱数を生成するために,メルセンヌ・ツイスタやPCG64などのアルゴリズムを選ぶことができる.
※ ライブラリのバージョンアップによって変わる可能性があるので,最新の情報は公式ドキュメントを参照すること.
# Scipyを用いて[0, 1)の一様乱数を生成する
sp.stats.uniform.rvs(size=10)
array([0.54552553, 0.21931384, 0.87670632, 0.22751795, 0.17759262,
0.8413425 , 0.43297564, 0.94800449, 0.50680963, 0.68071855])
# Numpyを用いて[0, 1)の一様乱数を生成する
rng = np.random.default_rng(123) # シードを123に設定
rng.random(10)
array([0.68235186, 0.05382102, 0.22035987, 0.18437181, 0.1759059 ,
0.81209451, 0.923345 , 0.2765744 , 0.81975456, 0.88989269])
4.1.2. 任意の確率分布に従う乱数#
逆関数法#
ある確率分布に従う乱数を生成したいとする. もし求めたい確率分布について,その累積分布関数が単調増加関数である場合,以下のアルゴリズムを用いることで,その確率分布に従う乱数を生成することができる. これを逆関数法と呼ぶ.
逆関数法のアルゴリズム
求めたい確率分布の累積分布関数 \( F(x) \) を求める.
\( F(x) \) の逆関数 \( F^{-1} \) を計算する.
\( [0, 1) \) の一様乱数 \( U \) に対し, \( F^{-1}(U) \) は求めたい確率分布に従う乱数である.
逆関数法の証明
\( [0, 1] \) の範囲の一様分布に従う確率変数(一様乱数)を \( U \) とすると,その累積分布関数は \( 0\le u \le 1 \) において
と表される. ここで,求めたい確率分布の累積分布関数 \( F(x) \) は単調増加関数であるので,その逆関数 \( F^{-1} \) が存在する. 特に,単調増加関数の逆関数は単調増加関数であるため,上の式は
と変形できる. よって,\( F^{-1}(u) = x \) と変数変換すれば,\( u = F(x) \) であるので,
を得る. 以上より,一様乱数 \( U \) に対して,新たな確率変数を \( X=F^{-1}(U) \) と定義すると,\( X \) の累積分布関数は求めたい確率分布の累積分布関数 \( F(x) \) になる.
例)指数分布
指数分布の確率密度関数は以下のように与えられる:
よって,その累積分布関数は
となり,その逆関数は \( F(x)=u \) と置くと,
と求まる. これより,[0, 1)の一様乱数 \( u \) に対して,\( -\mu \log(1-u) \) は指数分布に従うことが分かる.
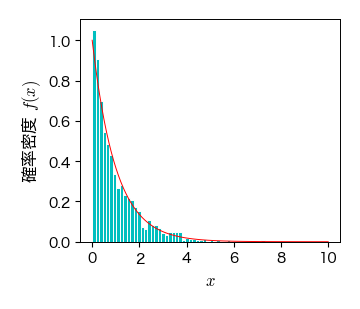
以下は,線形合同法を用いて生成した一様乱数から指数乱数を生成する例である.
# 線形合同法で[0, 1)の一様乱数を生成する
U = generagte_rand_u(seed=10, size=1000, umin=0, umax=1)
# 逆関数法で指数乱数に変換する
lmd = 1 # 指数分布のパラメータ
R_exp = -lmd*np.log(1-U)
# 生成した指数乱数からヒストグラムを描画する
fig, ax = plt.subplots()
ret = ax.hist(R_exp, bins=50, density=1, color='c', edgecolor='w')
# パラメータlmdの指数分布を描画する
x = np.linspace(0, 10, 100)
ax.plot(x, expon.pdf(x, scale=lmd), 'r-')
ax.set_xlabel('$ x $', fontsize=12)
ax.set_ylabel('確率密度 $ f(x) $', fontsize=12)
Text(0, 0.5, '確率密度 $ f(x) $')
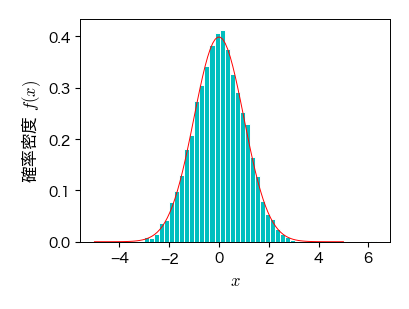
Box-Muller法(正規分布)#
正規分布の場合は,中心極限定理(後述)を用いた方法やボックス・ミュラー法が知られている. ボックスミュラー法は,\( [0, 1) \) の一様乱数 \( U_{1},\ U_{2} \) から標準正規分布に従う正規乱数 \( Z_{1},\ Z_{2} \) を生成することができる.
ボックスミュラー法のアルゴリズム
\( [0, 1) \) の一様乱数 \( U_1, U_2 \) を生成する.
以下の式で一様乱数を変換する:
\[\begin{align*} Z_1 &= \sqrt{-2 \log U_1} \cos(2 \pi U_2)\\ Z_2 &= \sqrt{-2 \log U_1} \sin(2 \pi U_2) \end{align*}\]\( Z_1, Z_2 \) は標準正規分布に従う.
# 線形合同法で[0, 1)の一様乱数を生成する
U1 = generagte_rand_u(seed=10, size=10000, umin=0, umax=1)
U2 = generagte_rand_u(seed=20, size=10000, umin=0, umax=1)
# Box-Muller法で正規乱数に変換する
Z1 = np.sqrt(-2*np.log(U1))*np.cos(2*np.pi*U2)
Z2 = np.sqrt(-2*np.log(U1))*np.sin(2*np.pi*U2)
fig, ax = plt.subplots(figsize=(4, 3))
# 生成した乱数によるヒストグラムの描画
ret1 = ax.hist(Z1, bins=50, density=1, color='c', edgecolor='w')
# 標準正規分布の描画
x = np.linspace(-5, 5, 100)
ax.plot(x, norm.pdf(x), 'r-')
ax.set_xlabel('$ x $', fontsize=12)
ax.set_ylabel('確率密度 $ f(x) $', fontsize=12)
Text(0, 0.5, '確率密度 $ f(x) $')
複雑な確率分布の場合#
逆関数法は累積分布関数の逆関数が求まる場合にしか適用できなかったが,どんな確率分布にも適用できる方法として,棄却法がある. また,マルコフ連鎖に基づいて任意の確率分布に従う乱数を生成するマルコフ連鎖モンテカルロ法(MCMC)は,主にベイズ推定を始めとして様々な分野で用いられている.
4.2. ベルヌーイ過程#
以下の条件を満たす試行をベルヌーイ試行と呼ぶ:
1回の試行において,起こりうる事象が2種類しかない
各事象が起こる確率は一定である
各試行は独立である
通常は,2種類の事象をそれぞれ成功(1),失敗(0)に対応付けた確率変数 \( U \) を考え,成功確率を \( p \),失敗確率を \( 1-p \) とする. このとき,確率変数 \( U \) の従う確率分布は
と表され,これをベルヌーイ分布と呼ぶ. 例えば,コイン投げは典型的なベルヌーイ試行であり,コインを1回投げたときの確率分布はベルヌーイ分布である.
ベルヌーイ試行を繰り返すとき,これをベルヌーイ過程と呼ぶ. 多くの基本的な確率分布はベルヌーイ過程を基に導くことができる. 以下にいくつかの例を示す.
二項分布:ベルヌーイ過程において,成功回数が従う確率分布.
正規分布:ベルヌーイ過程において,試行回数 \( n \) が十分大きい場合の成功回数の分布.
幾何分布:ベルヌーイ過程において,初めて成功するまでの失敗回数が従う確率分布.
負の二項分布:ベルヌーイ過程において, \( r \) 回目の成功が起こるまでの失敗回数が従う確率分布.
ポアソン分布:ベルヌーイ過程において,成功確率 \( p \) が小さく,試行回数 \( n \) が大きいときに \( np=一定 \) の条件の下で成功回数が従う確率分布.
4.2.1. 二項分布#
ベルヌーイ試行を \( n \) 回繰り返すとき,成功回数 \( X=\displaystyle\sum_{i=1}^{n} U_{i} \) を新たな確率変数とする. このとき,成功が \( x \) 回,失敗が \( n-x \) 回生じたとすると,その確率分布は二項分布
で与えられる. この式において,\( p^{x}(1-p)^{n-x} \) は成功が \( x \) 回,失敗が \( n-x \) 回生じる確率を意味する. また,\( \displaystyle\binom{n}{x} \) は \( n \) 個から \( x \) を取り出す組み合わせの数 \( _{n}C_{x} \) を表し,\( n \) 回の中で何回目に成功するかの場合の数に対応する. なお,\( n=1 \) の場合はベルヌーイ分布に対応する.
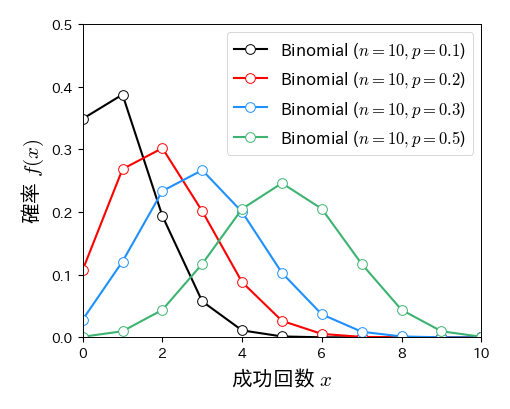
二項分布は試行回数 \( n \) と成功確率 \( p \) がパラメータであり,これらによって分布の形が決まる.
# 成功確率pを変化させた場合の二項分布の変化
fig, ax = plt.subplots(figsize=(5, 4))
k = np.arange(0, 20, 1)
for p in [0.1, 0.2, 0.3, 0.5]:
ax.plot(k, binom.pmf(k, n=10, p=p), '-o', mfc='w', ms=7, lw=1.5, label='Binomial ($n=10, p=%s$)' % p)
ax.set_xlim(0, 10); ax.set_ylim(0, 0.5)
ax.set_xlabel('成功回数 $x$', fontsize=15)
ax.set_ylabel('確率 $f(x)$', fontsize=15)
ax.legend(numpoints=1, fontsize=12, loc='upper right', frameon=True);
# 試行回数nを変化させた場合の二項分布の変化
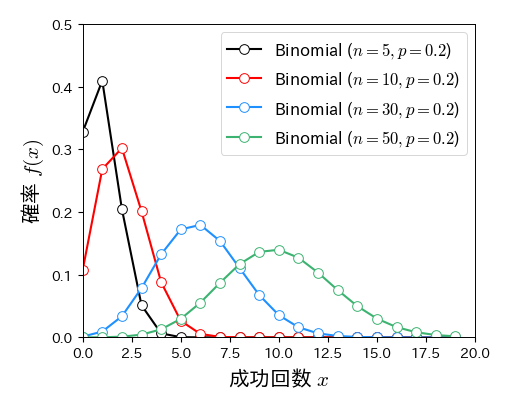
fig, ax = plt.subplots(figsize=(5, 4))
k = np.arange(0, 20, 1)
for n in [5, 10, 30, 50]:
ax.plot(k, binom.pmf(k, n=n, p=0.2), '-o', mfc='w', ms=7, lw=1.5, label='Binomial ($n=%s, p=0.2$)' % n)
ax.set_xlim(0, 20); ax.set_ylim(0, 0.5)
ax.set_xlabel('成功回数 $x$', fontsize=15)
ax.set_ylabel('確率 $f(x)$', fontsize=15)
ax.legend(numpoints=1, fontsize=12, loc='upper right', frameon=True);
4.2.2. ポアソン分布#
ベルヌーイ試行を \( n \) 回繰り返すとき,成功確率 \( p \) が小さく,かつ試行回数 \( n \) が大きい極限を考える. ただし,極限を取る際に平均値が一定値 \( np=\mu \) になるようにする. このような条件で成功回数 \( X \) が従う分布は,二項分布の式に \( np=\mu \) を代入し,極限 \( p\to 0,\ n\to \infty \) を取ることで
と求まる. これをポアソン分布と呼ぶ. ポアソン分布は1つのパラメータ \( \mu \) だけで特徴づけられ,期待値と分散はともに \( \mu \) となる.
ポアソン分布は,一定の期間内(例えば1時間や1日)に,稀な現象(\( p\to 0 \))を多数回試行(\( n\to \infty \))した場合にその発生回数が従う分布である. ポアソン分布が現れる例は無数にあり,「1日のコンビニの来店客数」,「1日の交通事故件数」,「1分間の放射性元素の崩壊数」,「1ヶ月の有感地震の回数」,「サッカーの試合における90分間の得点数」などは典型例である.
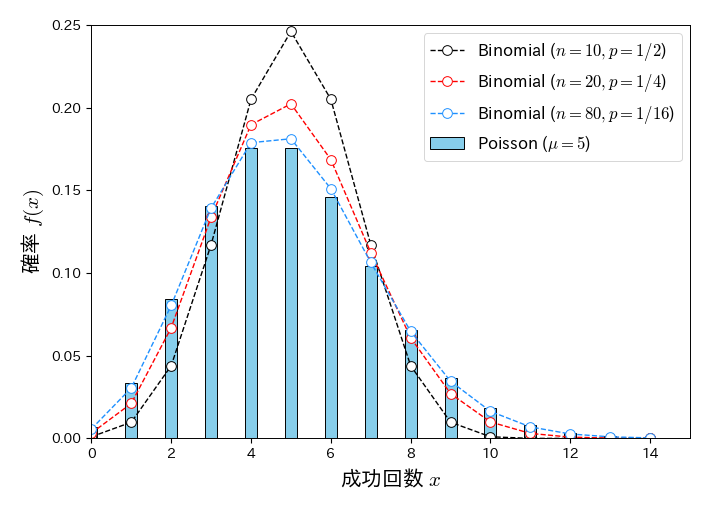
以下は \( np=5 \) に保って \( n \) を大きく,\( p \) を小さくしたときの二項分布(折れ線グラフ)と \( \mu=5 \) のポアソン分布(棒グラフ)の比較である. \( n=80,\ p=1/16 \) になると,二項分布とポアソン分布はほとんど一致していることが分かる.
fig, ax = plt.subplots(figsize=(7, 5))
x = np.arange(0, 15, 1)
# ポアソン分布
ax.bar(x, poisson.pmf(x, mu=5), width=0.3, color='skyblue', edgecolor='k', alpha=1, label='Poisson ($\mu=5$)')
# 二項分布
for i in [0, 1, 3]:
p, n = 1/2**(i+1), 10*2**i
ax.plot(x, binom.pmf(x, n=n, p=p), 'o--', mfc='w', ms=7, lw=1, label='Binomial ($n=%s, p=1/%s$)' % (n, 2**(i+1)))
ax.legend(numpoints=1, fontsize=12, loc='best', frameon=True, bbox_to_anchor=(1, 1))
ax.set_xlim(0, 15); ax.set_ylim(0, 0.25)
ax.set_xlabel('成功回数 $ x $', fontsize=15)
ax.set_ylabel('確率 $f(x)$', fontsize=15);
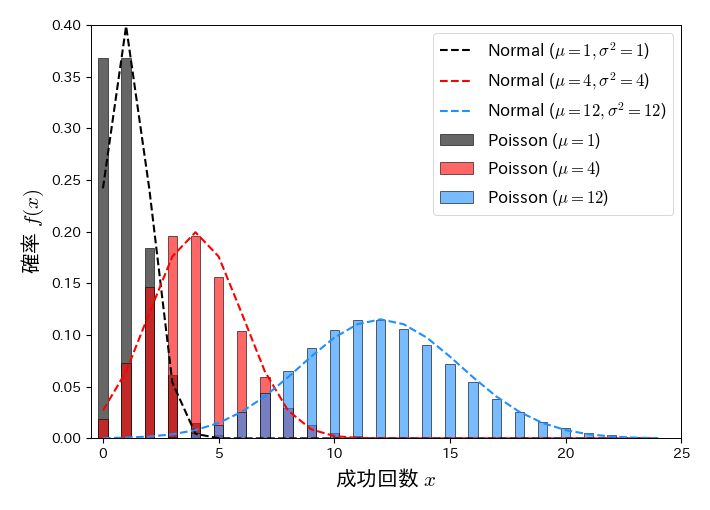
\( \mu \)が大きいとき
ポアソン分布は \( \mu \) を大きくすると平均と分散が共に \( \mu \) の正規分布に近づくことが知られている:
以下はパラメータ \( \mu \) を増加させた場合のポアソン分布(棒グラフ)と正規分布(破線)の比較である. \( \mu \) が大きくなるほどポアソン分布が正規分布に近づくことが確認できる.
fig, ax = plt.subplots(figsize=(7, 5))
k = np.arange(0, 25, 1)
for mu in [1, 4, 12]:
ax.bar(k, poisson.pmf(k, mu=mu), width=0.4, edgecolor='k', alpha=0.6, label='Poisson ($\mu=%s$)' % mu)
ax.plot(k, norm.pdf(k, loc=mu, scale=np.sqrt(mu)), '--', lw=1.5, label='Normal ($\mu=%s, \sigma^2=%s$)' % (mu, mu))
ax.set_xlim(-0.5, 25); ax.set_ylim(0, 0.4)
ax.set_xlabel('成功回数 $x$', fontsize=15)
ax.set_ylabel('確率 $f(x)$', fontsize=15)
ax.legend(numpoints=1, fontsize=12, loc='best', frameon=True);
4.2.3. 演習問題#
二項分布の期待値が \( np \),分散が \( np(1-p) \) となることを示せ.
二項分布からポアソン分布を導出せよ.
ポアソン分布の期待値と分散が共に \( \mu \) であることを示せ.
4.3. 大数の法則と中心極限定理#
4.3.1. 大数の法則#
ベルヌーイ過程の場合#
既にベルヌーイ過程における成功回数 \( X=\displaystyle\sum_{i=1}^{n} U_{i} \) が二項分布に従うことを見たが,ここでは \( U \) の標本平均(成功割合)
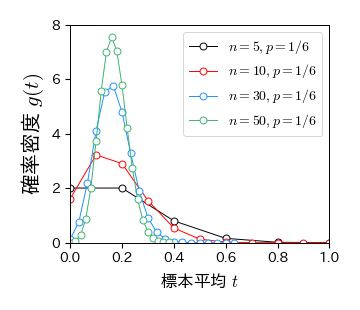
を新しい確率変数とする. このとき, \( T \) の確率分布を \( g(t) \) とすると,\( g(t) \) も二項分布に従い,\( g(t)=nf(nt) \) の関係にある.
次の例は成功確率を \( p=1/6 \) に固定して,試行回数 \( n \) を大きくしたときの標本平均 \( T \) の確率分布である(例えば,サイコロを振って1が出た場合に \( U=1 \) ,それ以外の場合に \( U=0 \) とした場合). この図を見ると,\( n \) の増加に伴って \( t=1/6 \) の周りに分布が集中するとともに,高さが大きくなる様子が分かる.
fig, ax = plt.subplots()
k = np.arange(0, 20, 1)
for n in [5, 10, 30, 50]:
ax.plot(k/n, n*binom.pmf(k, n=n, p=1/6), '-o', mfc='w', ms=5, label='$n=%s, p=1/6$' % n)
ax.set_xlim(0, 1); ax.set_ylim(0, 8)
ax.set_xlabel('標本平均 $t$', fontsize=12)
ax.set_ylabel('確率密度 $g(t)$', fontsize=15)
ax.legend(numpoints=1, fontsize=10, loc='upper right', frameon=True);
以上のような図の変化を数式で確認する. まず,成功回数 \( X \) の期待値と分散はそれぞれ \( E(X)=np,\ V(X)=np(1-p) \) であるから,成功割合 \( T=X/n \) の期待値と分散はそれぞれ \( E(T)=p,\ V(T)=p(1-p)/n \) となる. これより,成功割合 \( T=X/n \) の期待値は \( n \) に依らず一定 \( p \) で,分散は \( n \) とともに0に近づくことが分かる. これが,成功割合 \( T=X/n \) の分布が試行回数 \( n \) の増加とともに \( p \) の近くに集中する理由である.
以上のように,ベルヌーイ過程においては,試行回数 \( n\to \infty \) の極限で成功割合 \( T=X/n \) が理論値 \( p \) に一致する. このように,確率変数の標本平均が理論値に一致する性質は大数の法則と呼ばれている.
大数の法則(一般の場合)#
大数の法則は,一般の確率分布に従う確率変数列について成り立つ法則であり,以下のように表される.
大数の法則
独立同分布に従う \( n \) 個の確率変数 \( U_{1}, U_{2},\ldots, U_{n} \) に対し,それぞれの期待値(母平均)を \( \mu \) とする. このとき,確率変数列の標本平均 \( \displaystyle T=\frac{1}{n}\sum_{i=1}^{n}U_{i} \) は \( n\to\infty \) で \( \mu \) に一致する.
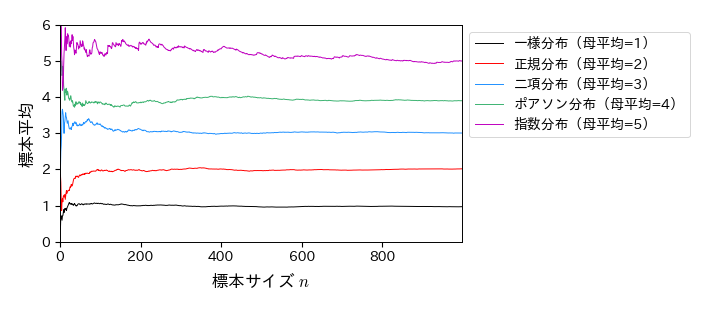
以下は,様々な確率分布に対する大数の法則のシミュレーションである.
N = np.arange(1, 1000)
# 様々な確率分布からサイズnの標本を生成する
U_uni = uniform.rvs(loc=0, scale=2, size=len(N)) # 一様分布(母平均1)
U_norm = norm.rvs(loc=2, scale=1, size=len(N)) # 正規分布(母平均2)
U_binom = binom.rvs(n=10, p=0.3, size=len(N)) # 二項分布(母平均3)
U_poisson = poisson.rvs(mu=4, size=len(N)) # ポアソン分布(母平均4)
U_expon = expon.rvs(scale=5, size=len(N)) # 指数分布(母平均5)
# 様々な標本サイズnに対して標本平均を計算
T_uni, T_norm, T_binom, T_poisson, T_expon = [], [], [], [], []
for n in N:
T_uni.append(U_uni[:n].mean())
T_norm.append(U_norm[:n].mean())
T_binom.append(U_binom[:n].mean())
T_poisson.append(U_poisson[:n].mean())
T_expon.append(U_expon[:n].mean())
# 標本平均の変化をプロット
fig, ax = plt.subplots(figsize=(7, 3))
ax.plot(N, np.array(T_uni), '-', label='一様分布(母平均=1)')
ax.plot(N, np.array(T_norm), '-', label='正規分布(母平均=2)')
ax.plot(N, np.array(T_binom), '-', label='二項分布(母平均=3)')
ax.plot(N, np.array(T_poisson), '-', label='ポアソン分布(母平均=4)')
ax.plot(N, np.array(T_expon), '-', label='指数分布(母平均=5)')
ax.set_xlim(0, len(N)); ax.set_ylim(0, 6)
ax.set_xlabel('標本サイズ $n$', fontsize=12)
ax.set_ylabel('標本平均', fontsize=12)
ax.legend(numpoints=1, fontsize=10, loc='upper left', frameon=True, bbox_to_anchor=(1, 1));
4.3.2. 中心極限定理#
ベルヌーイ過程において,\( n \) 回のベルヌーイ試行を1セットとして,成功回数 \( X \) や成功割合(標本平均) \( T \) を求める. これを何セットも繰り返すと,\( X \) や \( T \) の分布が得られ,いずれも二項分布に従うが,\( n \) を大きくしていくと左右非対称な分布から左右対称な分布へと変化する. このとき,\( n \) を十分大きくしたときに出現する左右対称で滑らかな分布は正規分布であることが知られている.
以上はベルヌーイ過程の場合であるが,実は一般の確率分布に従う確率変数列についても,\( n \) が十分大きいとき,確率変数列の和や標本平均は正規分布に近づくことが知られている. この性質は中心極限定理と呼ばれており,より具体的には以下のように表される.
中心極限定理
独立同分布に従う \( n \) 個の確率変数 \( U_{1}, U_{2},\ldots, U_{n} \) に対し,それぞれの母平均を \( \mu \),母分散を \( \sigma^2 < \infty \) とする.このとき,確率変数列の標本平均 \( \displaystyle T=\frac{1}{n}\sum_{i=1}^{n}U_{i} \) の分布 \( g(t) \) が \( n \) を大きくしたときに正規分布 \( N(\mu, \sigma^{2}/n) \) に近づく
ベルヌーイ分布の場合#
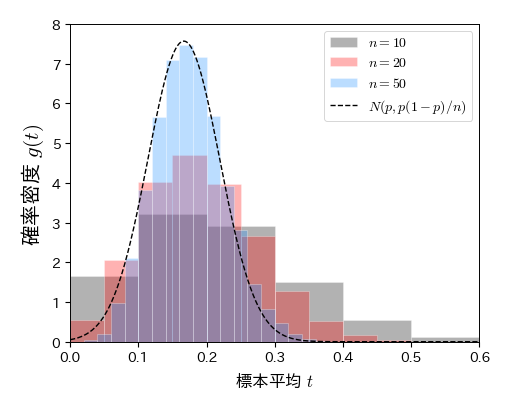
確率変数列 \( U_{1}, U_{2},\ldots, U_{n} \) が成功確率 \( p \) のベルヌーイ分布に従うとき,期待値は \( p \),分散は \( p(1-p) \)である. よって,中心極限定理によると, \( U \) の標本平均(成功割合)の分布は \( n \) を大きくしたときに正規分布 \( N(p, p(1-p)/n) \) に近づく.
# 標本平均を10000回計算する
p=1/6 # ベルヌーイ試行の成功確率
T10, T20, T50 = [], [], []
for j in range(10000):
# 確率pのベルヌーイ分布からサイズnの標本を生成
U10 = sp.stats.bernoulli.rvs(p, size=10)
U20 = sp.stats.bernoulli.rvs(p, size=20)
U50 = sp.stats.bernoulli.rvs(p, size=50)
# 標本平均を計算してリストに追加
T10.append(U10.mean())
T20.append(U20.mean())
T50.append(U50.mean())
# 標本平均のヒストグラムを描画
fig, ax = plt.subplots(figsize=(5, 4))
ax.hist(T10, bins=np.unique(T10), rwidth=1, density=1, edgecolor='w', alpha=0.3, label='$n=10$')
ax.hist(T20, bins=np.unique(T20), rwidth=1, density=1, edgecolor='w', alpha=0.3, label='$n=20$')
ax.hist(T50, bins=np.unique(T50), rwidth=1, density=1, edgecolor='w', alpha=0.3, label='$n=50$')
# 正規分布の確率密度関数を描画
t = np.arange(0, 1, 0.001)
gt = sp.stats.norm.pdf(t, loc=p, scale=np.sqrt(p*(1-p)/50))
ax.plot(t, gt, 'k--', lw=1, label='$N(p, p(1-p)/n)$')
ax.set_xlim(0, 0.6), ax.set_ylim(0, 8)
ax.set_xlabel('標本平均 $ t $ ', fontsize=12)
ax.set_ylabel('確率密度 $ g(t) $ ', fontsize=15)
ax.legend(numpoints=1, fontsize=10, loc='upper right', frameon=True);
指数分布の場合#
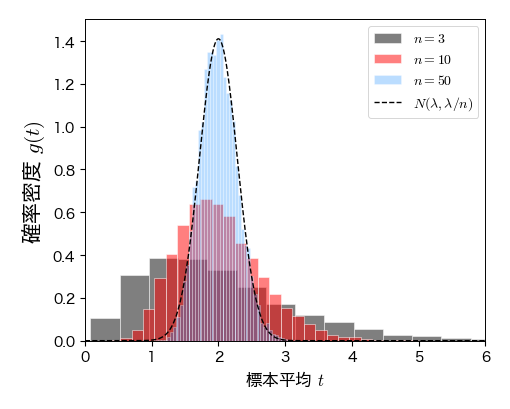
確率変数列 \( U_{1}, U_{2},\ldots, U_{n} \) がパラメータ \( \lambda \) の指数分布に従うとき,期待値は \( \lambda \),分散は \( \lambda^2 \) である. よって,中心極限定理によると, \( U \) の標本平均(成功割合)の分布は \( n \) を大きくしたときに正規分布 \( N(\lambda, \lambda^2/n) \) に近づく.
# 標本平均を10000回計算する
lmd=2 # 指数分布のパラメータ
T3, T10, T50 = [], [], []
for j in range(10000):
# パラメータlmdの指数分布からサイズnの標本を生成
U3 = sp.stats.expon.rvs(loc=0, scale=lmd, size=3)
U10 = sp.stats.expon.rvs(loc=0, scale=lmd, size=10)
U50 = sp.stats.expon.rvs(loc=0, scale=lmd, size=50)
# 標本平均を計算してリストに追加
T3.append(U3.mean())
T10.append(U10.mean())
T50.append(U50.mean())
# 標本平均のヒストグラムを描画
fig, ax = plt.subplots(figsize=(5, 4))
ax.hist(T3, bins=20, density=1, edgecolor='w', alpha=0.5, label='$n=3$')
ax.hist(T10, bins=30, density=1, edgecolor='w', alpha=0.5, label='$n=10$')
ret = ax.hist(T50, bins=50, density=1, edgecolor='w', alpha=0.3, label='$n=50$')
# 正規分布N(\mu, \sigma^2/n)の確率密度関数を描画
t = np.arange(0, 10, 0.01)
gt = sp.stats.norm.pdf(t, loc=lmd, scale=np.sqrt(lmd**2/50))
ax.plot(t, gt, 'k--', lw=1, label=r'$N(\lambda, \lambda/n)$')
ax.set_xlim(0, 6)
ax.set_xlabel('標本平均 $ t $ ', fontsize=12)
ax.set_ylabel('確率密度 $ g(t) $ ', fontsize=15)
ax.legend(numpoints=1, fontsize=10, loc='upper right', frameon=True);
4.3.3. サイコロを振る実験#
サイコロを振って1が出たら成功( \( U=1 \) ),それ以外は失敗( \( U=0 \) )とする. これを \( n \) 回繰り返すと,成功確率 \( p=1/6 \) のベルヌーイ過程となり,\( n \) を大きくすると \( U \) の標本平均(1が出た割合)は理論値 \( p \) に近づく(大数の法則). また,\( n \) を大きくすると \( U \) の標本平均(1が出た割合)の分布は正規分布 \( N(p, p(1-p)/n) \) に近づく(中心極限定理). 以上の性質を実際にサイコロを振る実験を行って確認せよ.
サイコロを振る実験
サイコロを \( n \) 回振ることを1セットとする. 今回の実験では,Excelの1行が1セットとなるように記録する.
グループに分かれて5個のサイコロを何度も振り,出た目をExcelファイルに記録せよ.
記録する際には,50個のサイコロの出目を記録するごとに次の行に移ること.
50行を目安にサイコロを振ること.
サイコロ実験の集計(Excel)
1セットの試行回数が \( n=10,20,50 \) の場合について,各セットで1が出た割合を計算せよ.
\( n=10,20,50 \) の場合について,1が出た割合のデータを全グループで統合し,csvファイルに保存せよ.
サイコロ実験の解析(Python)
csvファイルをPandasのDataFrameに読み込め.
\( n=10,20,50 \) の場合について,1が出た割合のヒストグラムを描け.
\( n=50 \) の場合について,正規分布 \( N(p, p(1-p)/n) \) を重ね描きし,中心極限定理を確認せよ.
過年度のデータがある場合は,それらのデータも一つに統合し,サンプル数を大きくして,中心極限定理を確認せよ.
4.4. マルコフ連鎖#
4.4.1. マルコフ連鎖の定式化#
ベルヌーイ過程は,1回の試行で取りうる状態が2つ(成功/失敗)だけで,それぞれの出現確率が一定値(\( p,\ 1-p \))であったが,これを次のように拡張する:
各時刻で取りうる状態が離散的で2つ以上
次の時刻に取りうる状態が現在の状態だけに依存して決まる(マルコフ性)
以上のような確率過程をマルコフ連鎖と呼ぶ.
遷移確率#
時刻 \( t \) の状態を確率変数 \( U_{t} \) によって表す. \( U_{t} \) は離散的な状態 \( \{0, 1, 2, \ldots\} \) を取るものとする(取りうる状態の集合を状態空間と呼ぶ). このとき,マルコフ性は以下のように表される:
これは,時刻 \( t+1 \) に状態 \( j \) を取る確率が,時刻 \( t \) の状態だけで決まることを表している. 以下ではこの確率を
と表し,これを状態 \( i \) から \( j \) への遷移確率と呼ぶ. また,遷移確率 \( p_{ij} \) を \( (i,j) \) 成分とする行列を遷移確率行列と呼び,\( P \) と表す. なお,遷移確率は時刻 \( t \) に依らず一定であるとする(これを時間的に一様なマルコフ連鎖と呼ぶ). マルコフ連鎖は,各状態間を遷移確率に従って次々に移動するようなイメージを持つと理解しやすい.
マルコフ連鎖の具体例として,状態空間が \( S=\{0, 1, 2\} \) の場合を考える. 図 4.1は,状態間の遷移確率を可視化したもので,状態遷移図と呼ばれる. この場合の遷移確率行列は次のように与えられる:
ここで,遷移確率行列は各行の和が必ず1になることに注意する. これは,次の時刻で必ずいずれかの状態に遷移することを意味している.
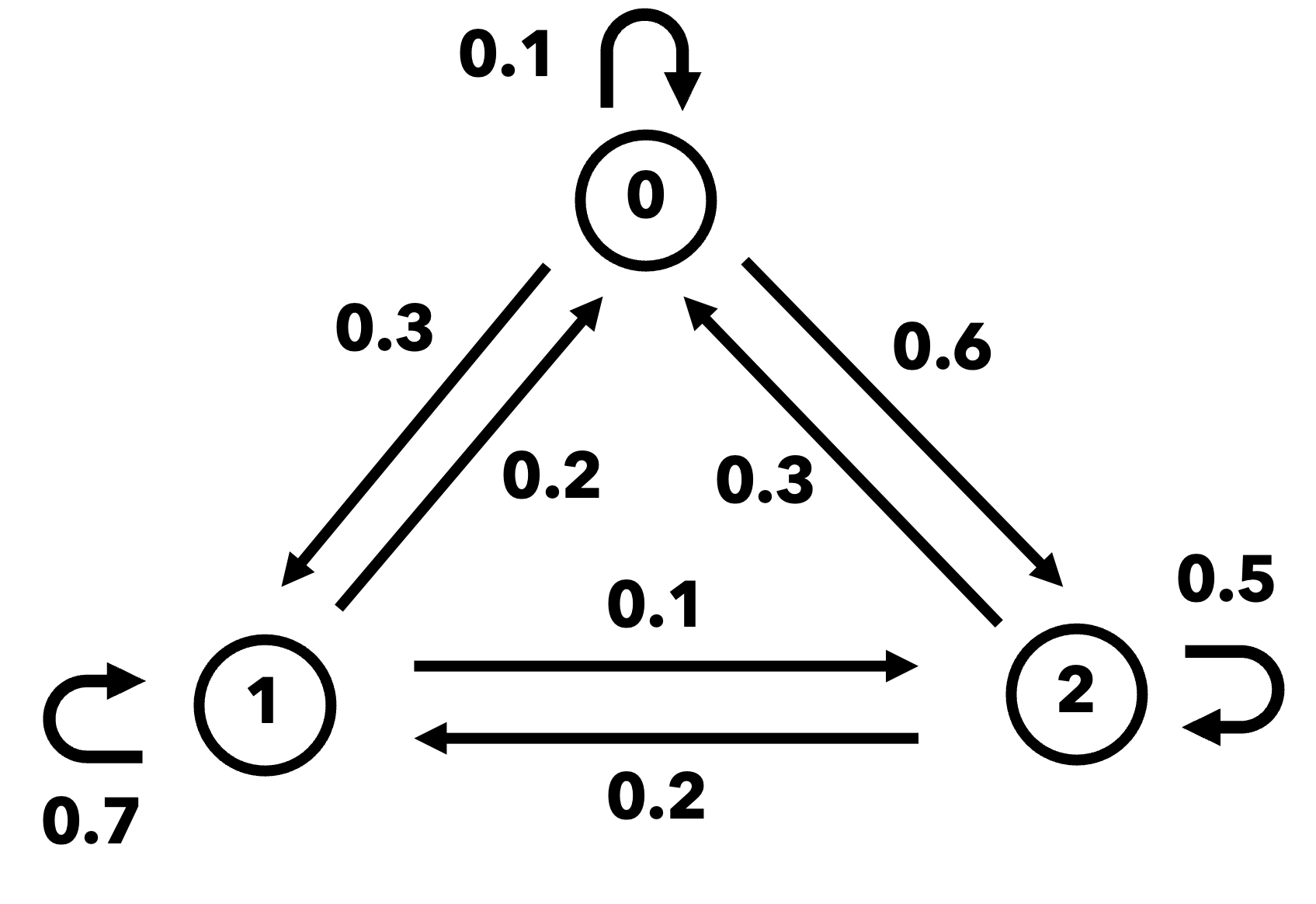
図 4.1 マルコフ連鎖の状態遷移図#
状態ベクトル#
時刻 \( t \) に状態 \( i \) を取る確率を
と表し,全状態を並べたベクトル \( \boldsymbol{w}_{t} \) を状態ベクトルと呼ぶ. 状態ベクトルは確率分布を表し,3状態の場合は \( \boldsymbol{w}_{t} = [w^{(t)}_{0}, w^{(t)}_{1}, w^{(t)}_{2}] \) と表される. (※ ベルヌーイ過程の場合,状態ベクトルはベルヌーイ分布を意味する.)
時刻 \( t+1 \) の状態ベクトル \( \boldsymbol{w}_{t+1} \) は,時刻 \( t \) の状態ベクトル \( \boldsymbol{w}_{t} \) と遷移確率行列 \( P \) を用いて
と表すことができる. すなわち,状態ベクトルは遷移確率行列をかけることで次の時刻の状態ベクトルに変化する. これより,初期状態ベクトル \( \boldsymbol{w}_{0} \) が与えられたとき,時刻 \( t \) の状態ベクトルは
と表される.
例えば,図 4.1の場合について,初期状態ベクトル \( \boldsymbol{w}_{0} = [1, 0, 0] \) が与えられたとき,時刻 \( 1 \) の状態ベクトルは次のようになる:
マルコフ連鎖の定常状態#
状態ベクトルは遷移を繰り返すことによって変化していくが,もしそれ以上変化しなくなった場合,これを定常状態と呼ぶ. 定常状態の状態ベクトル \( \boldsymbol{w} \) は遷移確率行列 \( P \) をかけても変化しないので,
という式を満たす. ここで,この式の両辺の転置を取ると,
となることから,\( \boldsymbol{w}^{\top} \) は行列\( P^{\top} \)の固有値1に対応する固有ベクトルであることが分かる. なお,行列 \( P^{\top} \) が固有値1を持つことは,以下の固有方程式を解くことで確認できる:
固有方程式の導出
以下の固有値問題を考える:
単位行列を \( I \) とすると,上式は次のように変形できる:
ここで,\( P^{\top} - \lambda I \) が逆行列を持つと(つまり正則だと), \( \boldsymbol{w}^{\top} = 0 \) という自明解しか持たないことになってしまう. よって,固有ベクトル \( \boldsymbol{w}^{\top} \) が0でない解を持つためには,\( P^{\top} - \lambda I \) が逆行列を持たないことが条件となる. この条件は,行列式が0になることと等価であるので,
と表され,これを固有方程式と呼ぶ.
4.4.2. マルコフ連鎖の例#
具体例#
あるスポーツにおいて,Aチームの得点を状態0,Bチームの得点を状態1で表す. Aチームが連続して得点する確率を0.8,Bチームが連続して得点する確率を0.7とすると,図 4.2 のような状態遷移図が得られ,遷移確率行列は次のように与えられる:
この遷移確率行列から,例えば,最初(時刻0)にAチームが得点した場合の時刻\( 2 \)における状態ベクトルは
となる.
定常分布は転置行列 \( P^{\top} \) の固有値1に対応する固有ベクトルとして求まる. まずは,\( P^{\top} \) が固有値1を持つことを確かめるため,固有値方程式
を解いてみる(\( I \) は単位行列). この固有値方程式は
となるのでこれを解くと,\( \lambda_{1}=1 \) と \( \lambda_{2}=0.5 \) が得られ,確かに固有値1を持つことが分かる.
次に,固有値1に対する固有ベクトルを求める. 関係式 \( P^{\top}\boldsymbol{w}^{\top}=\boldsymbol{w}^{\top} \) は
と書けるので,これより \( w_{1} = \frac{2}{3}w_{0} \) が得られる. よって,確率の条件 \( w_{0}+w_{1}=1 \) を満たすような固有ベクトルは
と求まる.
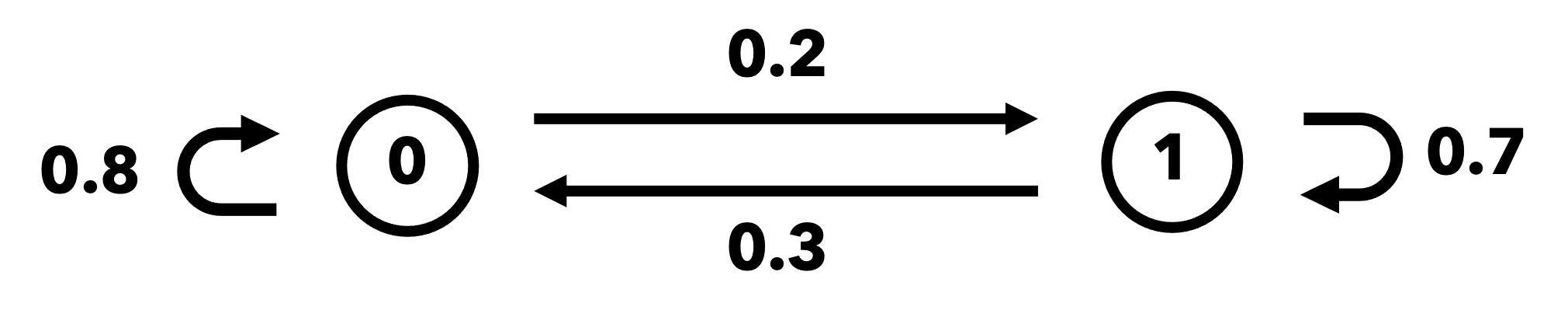
図 4.2 2状態マルコフ連鎖の状態遷移図#
応用例#
マルコフ連鎖は自然現象から社会現象に至るまで,様々な現象をモデル化するために用いられる.
株価変動のモデル
言語生成のモデル
球技におけるパス回しのモデル
また,具体的な現象のモデル以外にも多くの応用例がある.
GoogleのPageRank
マルコフ連鎖モンテカルロ法
4.4.3. Pythonによる実装#
以下のデータは,ある都市の30日間の天気を0(=晴れ),1(=曇),2(=雨)の3つの状態で表したものである.
data = [0,0,2,1,0,0,0,0,1,0,0,1,2,2,2,0,1,1,0,1,0,0,0,0,0,0,0,0,1,1]
遷移確率行列の推定
まず,遷移確率 \( p_{ij} \) を以下の式で推定する:
ここで,\( N_{ij} \) は状態 \( i \) から \( j \) への遷移回数,\( N_{i} \) は状態 \( i \) の出現回数である.
# 時刻kとk+1のデータをデータフレームに格納
df = pd.DataFrame({'t': data[:-1], 't+1': data[1:]})
df.head(3)
| t | t+1 | |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 2 |
| 2 | 2 | 1 |
# 遷移確率行列の推定
P = np.zeros([3, 3])
for i in range(3):
for j in range(3):
P[i, j] = len(df.loc[(df['t']==i) & (df['t+1']==j)])/len(df.loc[df['t']==i])
P
array([[0.66666667, 0.27777778, 0.05555556],
[0.57142857, 0.28571429, 0.14285714],
[0.25 , 0.25 , 0.5 ]])
マルコフ連鎖の計算
遷移確率行列 \( P \) が求まったら,任意の初期状態ベクトル \( \boldsymbol{w}_{0} \) と \( P \) との行列積を繰り返し計算すれば良い.
NumPy配列の行列積は np.dot() で計算できる.
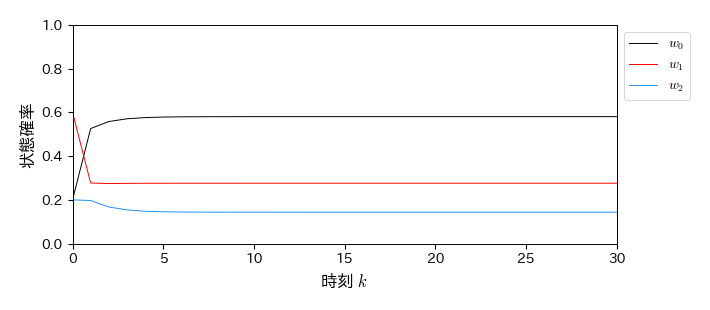
今回の遷移確率行列の場合は,どんな初期状態ベクトルに対しても,最終的には同じ定常状態に収束することが確認できる.
# 初期状態分布
w0 = np.array([0.2, 0.6, 0.2])
w0 = w0/np.sum(w0) # 規格化
# マルコフ連鎖の計算
W_all, w = w0, w0
for t in range(len(data)):
w = np.dot(w, P)
W_all = np.vstack([W_all, w])
w
array([0.58064516, 0.27598566, 0.14336918])
fig, ax = plt.subplots(figsize=(7, 3))
for i in range(3):
ax.plot(W_all[:, i], label='$w_%s$' % i)
ax.legend(loc='upper left', bbox_to_anchor=(1, 1), fontsize=10, frameon=True)
ax.set_xlabel('時刻 $k$', fontsize=12)
ax.set_ylabel('状態確率', fontsize=12)
ax.set_xlim(0, 30); ax.set_ylim(0, 1)
(0.0, 1.0)
4.4.4. 演習問題#
上の具体例で扱った2状態マルコフ連鎖について,定常状態の状態ベクトルを数値的に求めよ.
マルコフ連鎖の応用例について調べよ.