Pandasの基礎
Contents
# (必須)モジュールのインポート
import os
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
try:
import japanize_matplotlib
except:
pass
# 表示設定
np.set_printoptions(suppress=True, precision=3)
pd.set_option('display.precision', 3) # 小数点以下の表示桁
pd.set_option('display.max_rows', 150) # 表示する行数の上限
pd.set_option('display.max_columns', 5) # 表示する列数の上限
%precision 3
'%.3f'
# (必須)カレントディレクトリの変更(自分の作業フォルダのパスをコピーして入力する)
os.chdir(r'/Users/narizuka/work/document/lecture/rissho/sport_programming/sport_data')
本章は以下の文献とウェブサイトを参考にしています:
株式会社ロンバート・増田秀人,現場で使える!pandsデータ前処理入門,翔泳社,2020.
Wes McKinney, Pythonによるデータ分析入門,オライリー,2018
Jake VanderPlas, Pythonデータサイエンスハンドブック,オライリー,2018
4. Pandasの基礎#
4.1. Pandasとは?#
4.1.1. Pandasのインポート#
Pandas(パンダス)はpdという名前でインポートするのが慣例である:
import pandas as pd
4.1.2. PandasとNumPyの違い#
前章では,NumPyを用いて多次元配列を扱う方法を解説した.NumPyでは数値データの処理を非常に高速に実現することができた.一方,Pandas(パンダス)も基本的には多次元配列を扱うためのライブラリであり,PandasとNumPyを相互に変換することもできる.しかし,PandasにはNumPyと異なる以下のような特徴がある:
行と列にラベルが付与される
異なる型のデータ(数値や文字列)を扱うための機能を備えている
欠損値の処理やデータの整形のための機能を備えている
様々な形式のデータに対するファイル入出力機能を備えている
データの可視化機能を備えている
スポーツデータは文字列や数値など様々な型のデータを含み,分析を行うためにはデータを扱いやすい形に整形する必要がある. 例えば,以下は,典型的なサッカーのイベントデータをPandasに読み込んだものである.
pd.DataFrame({'t':[2, 64, 350, 600],
'player':['ozora', 'misaki', 'wakabayashi', 'hyuga'],
'position': ['MF', 'MF', 'GK', 'FW'],
'x':[5.0, 20.0, 10.5, 32.5],
'y':[10.0, 1.0, 50.5, 2.5]},
index = ['A', 'B', 'C', 'D'])
| t | player | position | x | y | |
|---|---|---|---|---|---|
| A | 2 | ozora | MF | 5.0 | 10.0 |
| B | 64 | misaki | MF | 20.0 | 1.0 |
| C | 350 | wakabayashi | GK | 10.5 | 50.5 |
| D | 600 | hyuga | FW | 32.5 | 2.5 |
このデータは1つの行が1イベントに対応しており,0から3までの行ラベル(=index)が付与されている.
また,各列には時刻(整数型),選手名(文字列型),位置座標(浮動小数),など異なるデータ型が混在しており,それぞれに"t","player","position","x","y"という列ラベル(=columns)が付与されている.
このデータを処理するためには,NumPyではなくPandasを用いた方が便利そうだと直感的に分かるだろう.
なお,ラベルの付いていない巨大な数値データを扱いたい場合や3次元以上の数値データを扱いたい場合など,NumPyを用いた方が良い場面ももちろんある. また,データの可視化はPandasでもできるが,より多機能なMatplotlibを用いることを推奨する.
4.2. DataFrameオブジェクト#
NumPyではデータをndarrayオブジェクト(NumPy配列)に格納し,様々な処理を行なった. Pandasでも2次元のデータを扱うための専用のオブジェクトDataFrameが用意されている. DataFrameは(Excelのような)テーブル形式の構造を持ち,以下の特徴がある:
各列には数値や文字列など異なる型を持たせることができる.
行と列にはラベルが付与されており,行方向のラベルをindex(インデックス),列方向のラベルをcolumns(カラム)と呼ぶ.
indexとcolumnsには数値や文字列を用いて任意のラベルを与えることができる.
行と列にはNumPy配列と同じ行番号・列番号も付与されており,行番号が増える方向を
axis=0,列番号が増える方向をaxis=1と呼ぶ.
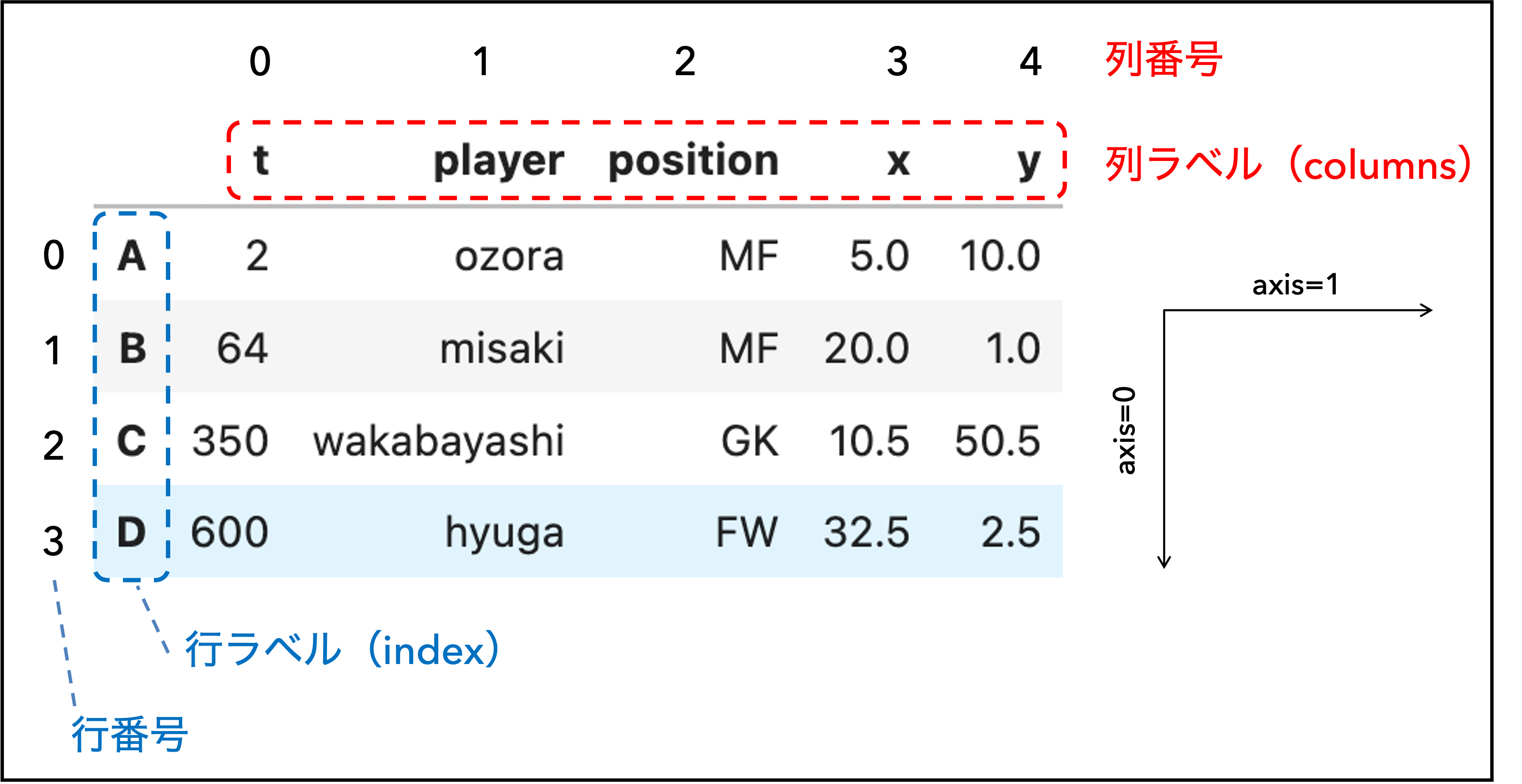
図 4.1 DataFrameの例#
4.2.1. DataFrameの生成#
DataFrameを生成するには,pd.DataFrame関数を用いる:
pd.DataFrame(data, index=[0, 1], columns=['A', 'B', 'C'])
pd.DataFrameの第1引数dataにはリスト,NumPy配列,辞書などを指定できる.
また,オプションとして,行ラベルを表すindexと列ラベルを表すcolumnsを指定することができる.
リスト・NumPy配列の変換
# リストの変換
pd.DataFrame([[1,2,3], [4,5,6]],
index=[0, 1],
columns=['A', 'B', 'C'])
| A | B | C | |
|---|---|---|---|
| 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 |
# NumPy配列の変換
pd.DataFrame(np.arange(6).reshape(2, 3),
index=[0, 1],
columns=['A', 'B', 'C'])
| A | B | C | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
辞書の変換
dataとして辞書を指定すると,辞書のkeyが列ラベルcolumnsとなる.
行ラベルindexはオプションとして指定する.
# 辞書データ
dict_data = {'t':[2, 64, 350, 600],
'player':['ozora', 'misaki', 'wakabayashi', 'hyuga'],
'x':[5.0, 20.0, 10.5, 32.5],
'y':[10.0, 1.0, 50.5, 2.5]}
list(dict_data.keys())
['t', 'player', 'x', 'y']
# 辞書による生成
pd.DataFrame(dict_data, index=['A', 'B', 'C', 'D'])
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
4.2.2. DataFrameのファイル入出力#
Pandasでデータ分析を行う場合,外部のファイルから直接データを読み込んだり,整形したデータを改めてファイルに保存することが多い.特に,データ分析で最もよく用いられるのがcsv形式のファイルである.csvとはカンマで区切られたテキストファイルを指す略称で,Excelで読み込むこともできる.
csvファイルに保存する
まず,DataFrameをcsvファイルに保存するにはto_csvメソッドを用いる:
df.to_csv('***/***.csv', option)
第1引数には保存先ファイルのパスを指定し,第2引数以降にオプションを指定する.
オプション名 |
説明 |
指定の仕方 |
|---|---|---|
header |
列ラベルの有無 |
True/False |
index |
行ラベルの有無 |
True/False |
encoding |
エンコーディング |
'utf-8', 'shift-jis'など |
columns |
出力する列 |
['A', 'B']など |
# DataFrameを生成する
df = pd.DataFrame({'t':[2, 64, 350, 600],
'player':['ozora', 'misaki', 'wakabayashi', 'hyuga'],
'x':[5.0, 20.0, 10.5, 32.5],
'y':[10.0, 1.0, 50.5, 2.5]},
index=['A', 'B', 'C', 'D'])
絶対パス
# 絶対パスを指定してcsvファイルに保存する
df.to_csv(r"C:\Users\parar\OneDrive\sport_data\4_pandas\df_sample.csv",\
header=True, index=True, encoding='shift-jis', columns=df.columns)
相対パス
# 相対パスを指定してcsvファイルに保存する
os.chdir(r'/Users/narizuka/work/document/lecture/rissho/sport_programming/sport_data') # カレントディレクトリをsport_dataに変更
df.to_csv('./4_pandas/df_sample.csv', # sport_dataからの相対パスを指定
header=True, index=True, encoding='utf-8', columns=df.columns)
csvファイルを読み込む
次に,csvファイルを読み込むにはpd.read_csv関数を用いる:
pd.read_csv('***/***.csv', option)
第1引数にcsvファイルのパスを指定し,第2引数以降にoptionを指定する.
オプション名 |
説明 |
指定の仕方 |
|---|---|---|
header |
列ラベルに使う行 |
行番号 |
names |
列ラベルの指定(header=Noneとともに使用) |
列ラベル |
index_col |
行ラベルに使う列 |
列番号/列名 |
usecols |
読み込む列 |
列番号/列名 |
skiprows |
除外する行 |
行番号 |
na_values |
欠損値で置き換える値(デフォルトでは' 'や'NaN'など) |
['None', '?']など |
na_filter |
欠損値での置き換えの有無(デフォルトはTrue) |
True/False |
encoding |
エンコーディング |
'utf-8', 'shift-jis'など |
絶対パス
# 絶対パスを指定してcsvファイルをDataFrameに読み込む
df = pd.read_csv(r"/Users/narizuka/work/document/lecture/rissho/sport_programming/sport_data/4_pandas/df_sample.csv",\
header=0, index_col=0, usecols=None)
df
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
相対パス
# 相対パスを指定してcsvファイルをDataFrameに読み込む
os.chdir(r'/Users/narizuka/work/document/lecture/rissho/sport_programming/sport_data') # カレントディレクトリをsport_dataに変更
df = pd.read_csv('./4_pandas/df_sample.csv', # sport_dataからの相対パスを指定
header=0, index_col=0, usecols=None)
df
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
4.2.3. 欠損値について#
欠損値とは?
データが何らかの事情で欠落している箇所を欠損値と呼ぶ.
Pandasにおいて,欠損値はNaNと表示される('Not a Number'の略).
Pandasではpythonの組み込み定数であるNoneやmath.nan,np.nanは全て欠損値として扱われる.
※ 無限大を表すinfはデフォルトでは欠損値として扱われない.
# 欠損値を含むDataFrame
import math
df = pd.DataFrame([[1., None, np.nan], [math.nan, 2, 3]])
df
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1.0 | NaN | NaN |
| 1 | NaN | 2.0 | 3.0 |
欠損値の検出
NaNの検出にはisnaメソッドまたはpd.isnull関数を用いる.どちらも動作は同じで,NaNの箇所がTrue,それ以外がFalseとなる.
df.isna()
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | False | True | True |
| 1 | True | False | False |
pd.isnull(df)
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | False | True | True |
| 1 | True | False | False |
欠損値の削除
欠損値の削除にはdropnaメソッドを用いる:
df.dropna(axis=0, how='any')
引数にaxis=0を指定した場合は行,axis=1の場合は列が削除される.
引数にhow='any'を指定した場合,行/列にNaNが1つでも含まれれば削除される.
一方,how='all'の場合,行/列の全ての要素がNaNの場合に削除される.
df = pd.DataFrame(np.array([[np.nan, 1, 2], [3, np.nan, 5], [6, 7, 8], [np.nan, np.nan, np.nan]]),
columns=['a', 'b', 'c'])
df
| a | b | c | |
|---|---|---|---|
| 0 | NaN | 1.0 | 2.0 |
| 1 | 3.0 | NaN | 5.0 |
| 2 | 6.0 | 7.0 | 8.0 |
| 3 | NaN | NaN | NaN |
# 欠損値を1つでも含む行を削除
df.dropna(axis=0, how='any')
| a | b | c | |
|---|---|---|---|
| 2 | 6.0 | 7.0 | 8.0 |
# 欠損値を1つでも含む列を削除
df.dropna(axis=1, how='any')
| 0 |
|---|
| 1 |
| 2 |
| 3 |
# 全ての要素が欠損値である行を削除
df.dropna(axis=0, how='all')
| a | b | c | |
|---|---|---|---|
| 0 | NaN | 1.0 | 2.0 |
| 1 | 3.0 | NaN | 5.0 |
| 2 | 6.0 | 7.0 | 8.0 |
欠損値の置換
欠損値NaNを他の値で置換するにはfillnaメソッドを用いる:
df.fillna(value=置換後の値)
valueに数値を指定すると,全ての欠損値がその数値で置換される.
# 欠損値を0で置換
df.fillna(0)
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 1.0 | 2.0 |
| 1 | 3.0 | 0.0 | 5.0 |
| 2 | 6.0 | 7.0 | 8.0 |
| 3 | 0.0 | 0.0 | 0.0 |
4.2.4. DataFrameの属性#
DataFrameに対して,df.属性名とすることで,dfの様々な情報を取得できる.
# DataFrameの読み込み
df = pd.read_csv('./4_pandas/df_sample.csv',\
header=0, index_col=0, usecols=None)
NumPy配列を取得:values属性
values属性を用いると,値をNumPy配列として取り出すことができる.
※ 複数の型が混在するDataFrameの場合,取り出したNumPy配列はobject型という特殊な型になる.
# 値をNumPy配列として取り出す
df.values
array([[2, 'ozora', 5.0, 10.0],
[64, 'misaki', 20.0, 1.0],
[350, 'wakabayashi', 10.5, 50.5],
[600, 'hyuga', 32.5, 2.5]], dtype=object)
行・列ラベルを取得:index属性,columns属性
DataFrameの行ラベルと列ラベルはindex属性とcolumns属性で抽出できる.
# 行ラベル
df.index
Index(['A', 'B', 'C', 'D'], dtype='object')
# 列ラベル
df.columns
Index(['t', 'player', 'x', 'y'], dtype='object')
その他の属性
DataFrameにはその他に以下の属性がある.
# DataFrameの要素数
df.size
16
# DataFrameの形状
df.shape
(4, 4)
# 各列のデータ型
df.dtypes
t int64
player object
x float64
y float64
dtype: object
4.2.5. DataFrameの参照#
DataFrameの一部を参照する方法として,主に以下がある:
行・列番号による参照:
iloc属性行・列ラベルによる参照:
loc属性,角括弧[]先頭・末尾から数行を抽出:
headメソッド,tailメソッド
以下で説明するように,基本的にはiloc属性とloc属性を用い,角括弧は列を選択する場合だけに使用することを推奨する.
特にloc属性を用いた参照方法はPandas特有であり,かつ頻繁に使用する.
# csvファイルをDataFrameに読み込む
df = pd.read_csv('./4_pandas/df_sample.csv',\
header=0, index_col=0, usecols=None)
df
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
行・列番号による参照:iloc属性
0から始まる要素番号(行番号と列番号)によって参照を行うには以下のようにiloc属性を用いる:
df.iloc[行番号, 列番号]
基本的にはNumPyのインデックス参照と同様であり,スライスにも対応している.
# 第1行の参照(列番号は省略可)
df.iloc[1]
t 64
player misaki
x 20.0
y 1.0
Name: B, dtype: object
# 第1列の参照(df['player']と同じ)
df.iloc[:, 1]
A ozora
B misaki
C wakabayashi
D hyuga
Name: player, dtype: object
# 第1~3行の参照
df.iloc[1:4]
| t | player | x | y | |
|---|---|---|---|---|
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
# 第1行と3行の参照
df.iloc[[1, 3]]
| t | player | x | y | |
|---|---|---|---|---|
| B | 64 | misaki | 20.0 | 1.0 |
| D | 600 | hyuga | 32.5 | 2.5 |
# 第0列〜2列の参照
df.iloc[:, :3]
| t | player | x | |
|---|---|---|---|
| A | 2 | ozora | 5.0 |
| B | 64 | misaki | 20.0 |
| C | 350 | wakabayashi | 10.5 |
| D | 600 | hyuga | 32.5 |
行・列ラベルによる参照:loc属性
行ラベルと列ラベルによって値を参照するには以下のようにloc属性を用いる:
df.loc['行ラベル', '列ラベル']
これはNumPyにはないPandas特有の方法である. なお,特定の行を参照する場合,列ラベルは省略できる.
# 'A'行を参照(列ラベルは省略可)
df.loc['A']
t 2
player ozora
x 5.0
y 10.0
Name: A, dtype: object
# 複数の行を参照
df.loc[['A', 'C']]
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
# 複数の列を参照(df[['x', 'y']]と同じ)
df.loc[:, ['x', 'y']]
| x | y | |
|---|---|---|
| A | 5.0 | 10.0 |
| B | 20.0 | 1.0 |
| C | 10.5 | 50.5 |
| D | 32.5 | 2.5 |
# 行ラベルが'A',列ラベルが't'の要素を参照
df.loc['A', 't']
2
# 複数の行ラベルと列ラベルの指定
df.loc[['A', 'C'], ['x', 'y']]
| x | y | |
|---|---|---|
| A | 5.0 | 10.0 |
| C | 10.5 | 50.5 |
角括弧[]による列の抽出
角括弧を使ってdf['t']とすることで't'というラベルの列を取り出すことができる.
※ スライスなどにも対応しているが,loc属性の使用を推奨
# 't'列の参照(df.loc[:, 't']と同じ)
df['t']
A 2
B 64
C 350
D 600
Name: t, dtype: int64
複数の列ラベルをリストで指定すると,複数の列を取り出すことができる.
# 'x'と'y'列の参照(df.loc[:, ['x', 'y']]と同じ)
df[['x', 'y']]
| x | y | |
|---|---|---|
| A | 5.0 | 10.0 |
| B | 20.0 | 1.0 |
| C | 10.5 | 50.5 |
| D | 32.5 | 2.5 |
先頭から数行だけ抽出:headメソッド
DataFramedfの先頭からn行だけ抽出したい場合はdf.head(n)とする.
# 先頭から2行だけ抽出
df.head(2)
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
末尾から数行だけ抽出:tailメソッド
DataFramedfの末尾からn行だけ抽出したい場合はdf.tail(n)とする.
# 末尾から2行だけ抽出
df.tail(2)
| t | player | x | y | |
|---|---|---|---|---|
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
4.2.6. (参考)Seriesオブジェクト#
Pandasには,DataFrameの他に1次元のデータを扱うためのSeriesオブジェクトが用意されている.DataFrameには行ラベルindexと列ラベルcolumnsが付与されたが,Seriesにはindexだけが付与される.SeriesはDataFrameから特定の1列を抜き出したものであり,基本的な操作方法はDataFrameと同じである.実際のデータ分析においてSeriesを単体で用いることはあまりないが,DataFrameを1列だけ取り出したり,ブールインデックスを扱ったりすると遭遇する.
SeriesはDataFrameから1列または1行を取り出すことで生成できる.
また,pd.Series関数により,リスト,NumPy配列,辞書などから生成することもできる.
df = pd.read_csv('./4_pandas/df_sample.csv',\
header=0, index_col=0, usecols=None)
df['t']
A 2
B 64
C 350
D 600
Name: t, dtype: int64
type(df['t'])
pandas.core.series.Series
# リストから作成
sr = pd.Series([0.25, 0.5, 0.75, 1.0],
index = ['A', 'B', 'C', 'D'])
sr
A 0.25
B 0.50
C 0.75
D 1.00
dtype: float64
Seriesオブジェクトの属性や参照の方法はDataFrameと同じである.
# NumPy配列に変換
sr.values
array([0.25, 0.5 , 0.75, 1. ])
# ラベルを取得
sr.index
Index(['A', 'B', 'C', 'D'], dtype='object')
# ラベル'A'の要素を取り出す
sr['A']
0.250
# loc属性でラベル'A'の要素を取り出す
sr.loc['A']
0.250
# iloc属性で0番目要素を取り出す
sr.iloc[0]
0.250
4.2.7. 演習問題#
次のcsvファイルをダウンロードし,作業フォルダ(例えばOneDrive/sport_data/4_pandas)に移動せよ:player_all.csv
このファイルには,2017年度にヨーロッパリーグ(イングランド,フランス,ドイツ,イタリア,スペイン)に所属していた選手のデータが保存されている.
※ 本データはPappalardoデータセットを加工したものである(詳細はイベントデータの解析).
まず,ダウンロードしたcsvファイルをdfに読み込む.
# index_col='player_id':選手IDを行ラベル(index)に設定
# na_values=0:身長`height`と体重`weight`が0の要素を欠損値`NaN`で置き換える
df = pd.read_csv('./4_pandas/player_all.csv', header=0, index_col='player_id', na_values=0)
df
| name | team_id | ... | birthday | league | |
|---|---|---|---|---|---|
| player_id | |||||
| 3319 | M_Özil | 1609 | ... | 1988/10/15 | England |
| 3560 | Nach_Monreal | 1609 | ... | 1986/02/26 | England |
| 7855 | L_Koscielny | 1609 | ... | 1985/09/10 | England |
| 7870 | A_Ramsey | 1609 | ... | 1990/12/26 | England |
| 7882 | P_Čech | 1609 | ... | 1982/05/20 | England |
| ... | ... | ... | ... | ... | ... |
| 266885 | M_Olunga | 756 | ... | 1994/03/26 | Spain |
| 282448 | Alei_García | 756 | ... | 1997/06/28 | Spain |
| 366374 | K_Soni | 756 | ... | 1998/04/17 | Spain |
| 443324 | Dougla_Luiz | 756 | ... | 1998/05/09 | Spain |
| 508686 | M_Lizak | 756 | ... | 1996/07/15 | Spain |
2439 rows × 10 columns
DataFrameの先頭2行を取得せよ
# 解答欄
DataFrameの末尾2行を取得せよ
# 解答欄
index(行ラベル)を取得せよ
# 解答欄
columns(列ラベル)を取得せよ
# 解答欄
iloc属性を用いて行番号が114の行を抽出せよ
# 解答欄
iloc属性を用いて行番号が1416~1936までの行を抽出せよ
※ これはイタリアリーグのデータである
# 解答欄
iloc属性を用いて列番号が4の列を抽出せよ
# 解答欄
iloc属性を用いて列番号が4以上の列を抽出せよ
# 解答欄
角括弧[]を用いてweight列を抽出せよ
# 解答欄
角括弧[]を用いてnationarity列を抽出せよ
# 解答欄
角括弧[]を用いてteam_id列,height列,weight列を抽出せよ
※ これがNumPyのレポート問題で扱ったデータである.
# 解答欄
loc属性を用いてindex(行ラベル)が703の行を抽出せよ
# 解答欄
loc属性を用いてweight列を抽出せよ
# 解答欄
loc属性を用いてindex(行ラベル)が61941,8747,283062の行を抽出せよ
※ これは身長2m以上の選手のデータである
# 解答欄
loc属性を用いてindex(行ラベル)が703でcolumns(列ラベル)がname,weight,heightの要素を抽出せよ
# 解答欄
index(行ラベル)が以下の番号の選手は全て日本人である:
94764, 703, 14763, 94695, 94831, 254649, 14816, 14749, 391606, 94650, 14929, 365880, 14836, 94828
これらの選手を以下の方法で抽出せよ.
# 上のindexの順番で抽出
# indexを昇順に並び替えた上で抽出
# 上のindexの順番で`name`列だけを抽出
# 上のindexの順番で`name`, `height`, `weight`列を抽出
4.3. 条件付き抽出#
DataFrameからある条件を満たす行や列を抽出する方法として,ブールインデックス参照がある.
※ この他にもwhereメソッド,queryメソッドなどがある.
4.3.1. ブールインデックスの取得#
DataFrameにおけるブールインデックス参照は基本的にはNumPyと同様である.
df = pd.read_csv('./4_pandas/df_sample.csv',\
header=0, index_col=0, usecols=None)
df
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
NumPyと同様に,==, >, <, %などの比較演算子を用いると,ブール値のSeriesまたはDataFrameを自動的に取得することができる.
# 't'列の値が64
df['t']==64
A False
B True
C False
D False
Name: t, dtype: bool
# 't'列の値が64より大きい
df['t']>64
A False
B False
C True
D True
Name: t, dtype: bool
# 'x'列の値が'y'列の値より大きい
df['x'] > df['y']
A False
B True
C False
D True
dtype: bool
複数条件の場合は(条件1) & (条件2)や(条件1)|(条件2)のように各条件を()で囲む(and, or, notは使えない)
# 't'列が64より大きくかつ'player'列が'hyuga'
(df['t']>64) & (df['player'] == 'hyuga')
A False
B False
C False
D True
dtype: bool
# 'player'列が'misaki'または'hyuga'
(df['player']=='misaki') | (df['player']=='hyuga')
A False
B True
C False
D True
Name: player, dtype: bool
ある条件の否定は~条件で実現できる.この表記は条件が多い場合に役立つ.
# 't'列が64でない(df['t']!=64と同じ)
~(df['t']==64)
A True
B False
C True
D True
Name: t, dtype: bool
4.3.2. ブールインデックス参照#
NumPyと同様,以下のようにブールインデックスがTrueの行だけを抽出することができる:
df.loc[条件, ['列ラベル1', '列ラベル2']]
特に,条件の次に列ラベルを指定すると,条件を満たす特定の列だけを抽出できる.
# 't'列の値が64の行
df.loc[df['t']==64]
| t | player | x | y | |
|---|---|---|---|---|
| B | 64 | misaki | 20.0 | 1.0 |
# 't'列の値が64の行で,'x','y'列のみ抽出
df.loc[df['t']==64, ['x', 'y']]
| x | y | |
|---|---|---|
| B | 20.0 | 1.0 |
# 't'列が64でない行(df['t']!=64と同じ)
df.loc[~(df['t']==64)]
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
# 't'列が64より大きくかつ'player'列が'hyuga'である行
df.loc[(df['t']>64) & (df['player'] == 'hyuga')]
| t | player | x | y | |
|---|---|---|---|---|
| D | 600 | hyuga | 32.5 | 2.5 |
# 'player'列が'misaki'または'hyuga'である行で,'x','y'列のみ抽出
df.loc[(df['player']=='misaki') | (df['player']=='hyuga'), ['x', 'y']]
| x | y | |
|---|---|---|
| B | 20.0 | 1.0 |
| D | 32.5 | 2.5 |
# 'x'列の値が'y'列の値より大きい行
df.loc[df['x'] > df['y']]
| t | player | x | y | |
|---|---|---|---|---|
| B | 64 | misaki | 20.0 | 1.0 |
| D | 600 | hyuga | 32.5 | 2.5 |
# 'x'列の値が'y'列の値より大きい行で'player'列のみ抽出
df.loc[df['x'] > df['y'], ['player']]
| player | |
|---|---|
| B | misaki |
| D | hyuga |
4.3.3. ブールインデックス参照による値の変更#
ブールインデックス参照で抽出したDataFrameに値を代入することで,条件を満たす要素だけ変更することができる.
# 't'==64の'player'を'wakashimazu'に変更
df2 = df.copy()
df2.loc[df['t']==350, 'player'] = 'wakashimazu'
df2
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakashimazu | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
# 't'>64の'x'と'y'を0に変更
df2 = df.copy()
df2.loc[df['t'] > 64, ['x', 'y']] = 0
df2
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 0.0 | 0.0 |
| D | 600 | hyuga | 0.0 | 0.0 |
4.3.4. 演習問題#
次のcsvファイルをダウンロードし,作業フォルダ(例えばOneDrive/sport_data/4_pandas)に移動せよ:player_all.csv
このファイルには,2017年度にヨーロッパリーグ(イングランド,フランス,ドイツ,イタリア,スペイン)に所属していた選手のデータが保存されている.
※ 本データはPappalardoデータセットを加工したものである(詳細はイベントデータの解析).
# index_col='player_id':選手IDを行ラベル(index)に設定
# na_values=0:身長`height`と体重`weight`が0の要素を欠損値`NaN`で置き換える
df = pd.read_csv('./4_pandas/player_all.csv', header=0, index_col='player_id', na_values=0)
df
| name | team_id | ... | birthday | league | |
|---|---|---|---|---|---|
| player_id | |||||
| 3319 | M_Özil | 1609 | ... | 1988/10/15 | England |
| 3560 | Nach_Monreal | 1609 | ... | 1986/02/26 | England |
| 7855 | L_Koscielny | 1609 | ... | 1985/09/10 | England |
| 7870 | A_Ramsey | 1609 | ... | 1990/12/26 | England |
| 7882 | P_Čech | 1609 | ... | 1982/05/20 | England |
| ... | ... | ... | ... | ... | ... |
| 266885 | M_Olunga | 756 | ... | 1994/03/26 | Spain |
| 282448 | Alei_García | 756 | ... | 1997/06/28 | Spain |
| 366374 | K_Soni | 756 | ... | 1998/04/17 | Spain |
| 443324 | Dougla_Luiz | 756 | ... | 1998/05/09 | Spain |
| 508686 | M_Lizak | 756 | ... | 1996/07/15 | Spain |
2439 rows × 10 columns
身長(height)が2m以上の選手を抽出せよ
# 解答欄
国籍(nationality)が日本の選手を抽出せよ
# 解答欄
国籍(nationality)がケニアの選手を抽出せよ
# 解答欄
出生地(birth_area)がケニアの選手を抽出せよ
# 解答欄
利き足(foot)が右(right)の選手の身長と体重を抽出せよ
# 解答欄
スペインリーグに所属し,ポジション(role)がフォワードの選手を抽出せよ
※ まずdf['role'].unique()によって,role列に含まれる値を確認する
# まず,role列の値を確認する
df['role'].unique()
array(['MD', 'DF', 'GK', 'FW'], dtype=object)
# 解答欄
所属リーグ名(league)と出生地名(birth_area)が同じ選手を抽出し,先頭から10行だけ表示せよ
# 解答欄
league列内のEnglandをイングランドに変更せよ
# 解答欄
イタリアリーグのデータだけ抽出し,player_Italy.csvという名前でcsvファイルに保存せよ.
# 解答欄
自分の好きな条件でデータを抽出せよ
# 解答欄
4.4. データの演算と集計#
4.4.1. 演算規則#
まず,NumPyの演算規則は以下のようにまとめられた:
NumPy配列と数値の演算は,配列の全ての要素に演算が適用される
同じ形状を持つ2つの配列の演算は,各配列の同じ要素同士で演算が行われる.
異なる形状を持つ配列の演算には特別な規則(ブロードキャスト)が適用される.
Pandasの基本的な演算規則はNumPyと似ているが,DataFrame(Series)にはラベルが付与されているのでやや挙動が異なる.
四則演算については+,-,/,*などの演算子で実現できるが,df.addやdf.subなどの算術メソッドを用いると,より細かい制御が可能である.
df1 = pd.DataFrame(np.arange(12).reshape(4, 3), columns=['a', 'b', 'c'], dtype='float')
df1
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 1.0 | 2.0 |
| 1 | 3.0 | 4.0 | 5.0 |
| 2 | 6.0 | 7.0 | 8.0 |
| 3 | 9.0 | 10.0 | 11.0 |
df2 = pd.DataFrame(2*np.ones(15).reshape(5, 3), columns=['a', 'b', 'd'])
df2
| a | b | d | |
|---|---|---|---|
| 0 | 2.0 | 2.0 | 2.0 |
| 1 | 2.0 | 2.0 | 2.0 |
| 2 | 2.0 | 2.0 | 2.0 |
| 3 | 2.0 | 2.0 | 2.0 |
| 4 | 2.0 | 2.0 | 2.0 |
数値との演算
DataFrame(およびSeries)と数値の演算は全ての要素に演算が適用される.
# 1を足す
df1 + 1
| a | b | c | |
|---|---|---|---|
| 0 | 1.0 | 2.0 | 3.0 |
| 1 | 4.0 | 5.0 | 6.0 |
| 2 | 7.0 | 8.0 | 9.0 |
| 3 | 10.0 | 11.0 | 12.0 |
# 1を足す(addメソッドを用いる)
df1.add(1)
| a | b | c | |
|---|---|---|---|
| 0 | 1.0 | 2.0 | 3.0 |
| 1 | 4.0 | 5.0 | 6.0 |
| 2 | 7.0 | 8.0 | 9.0 |
| 3 | 10.0 | 11.0 | 12.0 |
# 2を掛ける
df1 * 2
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 2.0 | 4.0 |
| 1 | 6.0 | 8.0 | 10.0 |
| 2 | 12.0 | 14.0 | 16.0 |
| 3 | 18.0 | 20.0 | 22.0 |
# 2を掛ける(mulメソッドを用いる)
df1.mul(2)
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 2.0 | 4.0 |
| 1 | 6.0 | 8.0 | 10.0 |
| 2 | 12.0 | 14.0 | 16.0 |
| 3 | 18.0 | 20.0 | 22.0 |
列(Series)同士の演算
# 'a'列と'b'列の和
df1['a'] + df1['b']
0 1.0
1 7.0
2 13.0
3 19.0
dtype: float64
# 'a'列と'b'列の積
df1['a'] * df1['b']
0 0.0
1 12.0
2 42.0
3 90.0
dtype: float64
# 'a'列と'b'列の割り算
df1['a'] / df1['b']
0 0.000
1 0.750
2 0.857
3 0.900
dtype: float64
# 'c'列を2乗する
df1['c']**2
0 4.0
1 25.0
2 64.0
3 121.0
Name: c, dtype: float64
# 'a'列から5を引いて2乗する
(df1['a'] - 5)**2
0 25.0
1 4.0
2 1.0
3 16.0
Name: a, dtype: float64
DataFrame同士の演算
行ラベル(index)と列ラベル(columns)が同じ要素同士で演算が行われる.
異なるラベルが存在する場合は列と行が拡張され,欠損値NaNとなる.
# ラベルが同じDataFrame同士の足し算
df1+df1
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 2.0 | 4.0 |
| 1 | 6.0 | 8.0 | 10.0 |
| 2 | 12.0 | 14.0 | 16.0 |
| 3 | 18.0 | 20.0 | 22.0 |
# ラベルが異なるDataFrame間の足し算
df1+df2
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 2.0 | 3.0 | NaN | NaN |
| 1 | 5.0 | 6.0 | NaN | NaN |
| 2 | 8.0 | 9.0 | NaN | NaN |
| 3 | 11.0 | 12.0 | NaN | NaN |
| 4 | NaN | NaN | NaN | NaN |
DataFrameとSeries(特定の列)の演算
df1
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 1.0 | 2.0 |
| 1 | 3.0 | 4.0 | 5.0 |
| 2 | 6.0 | 7.0 | 8.0 |
| 3 | 9.0 | 10.0 | 11.0 |
s1 = df1['c']
s1
0 2.0
1 5.0
2 8.0
3 11.0
Name: c, dtype: float64
DataFrameの各列とSeriesの演算を行いたい場合は算術メソッドを用いてaxis=0を指定する.
※ 各種算術メソッドでは,デフォルトでaxis=1となっているので注意.
# 各列にs1を加える
df1.add(s1, axis=0)
| a | b | c | |
|---|---|---|---|
| 0 | 2.0 | 3.0 | 4.0 |
| 1 | 8.0 | 9.0 | 10.0 |
| 2 | 14.0 | 15.0 | 16.0 |
| 3 | 20.0 | 21.0 | 22.0 |
# 各列からs1を引く
df1.sub(s1, axis=0)
| a | b | c | |
|---|---|---|---|
| 0 | -2.0 | -1.0 | 0.0 |
| 1 | -2.0 | -1.0 | 0.0 |
| 2 | -2.0 | -1.0 | 0.0 |
| 3 | -2.0 | -1.0 | 0.0 |
# 各列をs1で割る
df1.div(s1, axis=0)
| a | b | c | |
|---|---|---|---|
| 0 | 0.000 | 0.500 | 1.0 |
| 1 | 0.600 | 0.800 | 1.0 |
| 2 | 0.750 | 0.875 | 1.0 |
| 3 | 0.818 | 0.909 | 1.0 |
# 各列にs1を掛ける
df1.mul(s1, axis=0)
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 2.0 | 4.0 |
| 1 | 15.0 | 20.0 | 25.0 |
| 2 | 48.0 | 56.0 | 64.0 |
| 3 | 99.0 | 110.0 | 121.0 |
4.4.2. データの集計#
PandasにもNumPyと同様にデータの集計を行う様々なメソッドが用意されている.
各メソッドで集計の方向を指定するにはaxis引数を用いる.
列ごとに集計したい場合はaxis=0,行ごとの場合はaxis=1を指定する.
メソッド |
説明 |
option |
|---|---|---|
min |
最小値 |
|
max |
最大値 |
|
sum |
合計 |
|
mean |
平均値 |
|
median |
中央値 |
|
mode |
最頻値 |
|
var |
分散 |
ddof(不偏:1,標本:0) |
std |
標準偏差 |
ddof(不偏:1,標本:0) |
count |
NA値ではない要素数 |
|
diff |
階差 |
periods(何行前との差を取るか) |
cumusum |
累積和 |
df = pd.DataFrame(np.random.randint(0, 100, [5, 4]),
columns=list('abcd'))
df
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 69 | 88 | 23 | 20 |
| 1 | 96 | 97 | 75 | 28 |
| 2 | 92 | 91 | 65 | 51 |
| 3 | 91 | 11 | 81 | 90 |
| 4 | 2 | 12 | 47 | 62 |
# 各列の最大値
df.max(axis=0)
a 96
b 97
c 81
d 90
dtype: int64
# 各行の最大値
df.max(axis=1)
0 88
1 97
2 92
3 91
4 62
dtype: int64
# 各列の和
df.sum(axis=0)
a 350
b 299
c 291
d 251
dtype: int64
# 各行の和
df.sum(axis=1)
0 200
1 296
2 299
3 273
4 123
dtype: int64
# 各列の平均
df.mean(axis=0)
a 70.0
b 59.8
c 58.2
d 50.2
dtype: float64
# 各行の平均
df.mean(axis=1)
0 50.00
1 74.00
2 74.75
3 68.25
4 30.75
dtype: float64
# 各列の標本標準偏差
df.std(ddof=0, axis=0)
a 35.287
b 39.544
c 21.037
d 25.015
dtype: float64
# 1行前との差分
df.diff(periods=1, axis=0)
| a | b | c | d | |
|---|---|---|---|---|
| 0 | NaN | NaN | NaN | NaN |
| 1 | 27.0 | 9.0 | 52.0 | 8.0 |
| 2 | -4.0 | -6.0 | -10.0 | 23.0 |
| 3 | -1.0 | -80.0 | 16.0 | 39.0 |
| 4 | -89.0 | 1.0 | -34.0 | -28.0 |
条件付き抽出したデータの集計
まず,演習問題で扱った"player_all.csv"をdfに読み込む
df = pd.read_csv('./4_pandas/player_all.csv', header=0, index_col='player_id', na_values=0)
df
| name | team_id | ... | birthday | league | |
|---|---|---|---|---|---|
| player_id | |||||
| 3319 | M_Özil | 1609 | ... | 1988/10/15 | England |
| 3560 | Nach_Monreal | 1609 | ... | 1986/02/26 | England |
| 7855 | L_Koscielny | 1609 | ... | 1985/09/10 | England |
| 7870 | A_Ramsey | 1609 | ... | 1990/12/26 | England |
| 7882 | P_Čech | 1609 | ... | 1982/05/20 | England |
| ... | ... | ... | ... | ... | ... |
| 266885 | M_Olunga | 756 | ... | 1994/03/26 | Spain |
| 282448 | Alei_García | 756 | ... | 1997/06/28 | Spain |
| 366374 | K_Soni | 756 | ... | 1998/04/17 | Spain |
| 443324 | Dougla_Luiz | 756 | ... | 1998/05/09 | Spain |
| 508686 | M_Lizak | 756 | ... | 1996/07/15 | Spain |
2439 rows × 10 columns
# 国籍が'Japan'の選手の平均身長
df.loc[df['nationality']=='Japan', ['height']].mean()
height 176.786
dtype: float64
# 国籍が'England'の選手の平均身長
df.loc[df['nationality']=='England', ['height']].mean()
height 182.402
dtype: float64
# 右利きの選手の平均身長と平均体重
df.loc[df['foot']=='right', ['height', 'weight']].mean()
height 182.748
weight 76.712
dtype: float64
# 左利きの選手の平均身長と平均体重
df.loc[df['foot']=='left', ['height', 'weight']].mean()
height 181.560
weight 75.358
dtype: float64
# 身長が最大の選手
df.loc[df['height']==df['height'].max()]
| name | team_id | ... | birthday | league | |
|---|---|---|---|---|---|
| player_id | |||||
| 283062 | V_Milinković-Savić | 3185 | ... | 1997/02/20 | Italy |
1 rows × 10 columns
# 体重が最大の選手
df.loc[df['weight']==df['weight'].max()]
| name | team_id | ... | birthday | league | |
|---|---|---|---|---|---|
| player_id | |||||
| 8488 | W_Morgan | 1631 | ... | 1984/01/21 | England |
| 8726 | A_Begović | 1659 | ... | 1987/06/20 | England |
2 rows × 10 columns
4.5. データの整形#
df = pd.read_csv('./4_pandas/df_sample.csv',\
header=0, index_col=0, usecols=None)
df
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
4.5.1. 行・列の追加と削除#
行・列の追加:拡張代入
DataFrameに値を代入する際に存在しない行ラベルや列ラベルを指定すると,新たな行や列が追加される.
これを拡張代入と呼ぶ.
拡張代入はloc属性と角括弧による参照が対応している(iloc属性は対応していない).
※ この他に,列を追加するassinメソッド,行を追加するappendメソッドがあるがここでは触れない.
# loc属性による'z'列の追加
df2 = df.copy()
df2.loc[:, 'z'] = 5
df2
| t | player | x | y | z | |
|---|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 | 5 |
| B | 64 | misaki | 20.0 | 1.0 | 5 |
| C | 350 | wakabayashi | 10.5 | 50.5 | 5 |
| D | 600 | hyuga | 32.5 | 2.5 | 5 |
# 角括弧による'z'列の追加
df2 = df.copy()
df2['z'] = [1,2,3,4]
df2
| t | player | x | y | z | |
|---|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 | 1 |
| B | 64 | misaki | 20.0 | 1.0 | 2 |
| C | 350 | wakabayashi | 10.5 | 50.5 | 3 |
| D | 600 | hyuga | 32.5 | 2.5 | 4 |
# loc属性による'E'行の追加
df2 = df.copy()
df2.loc['E'] = [1000, 'ishizaki', 50.0, 20.0]
df2
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
| E | 1000 | ishizaki | 50.0 | 20.0 |
行・列の削除:dropメソッド
列を削除する場合はdf.drop(columns=['列名1', '列名2'])とする.
行を削除する場合はdf.drop(index=['行名1', '行名2'])とする.
※ バージョン0.21.0より前の場合はaxis引数を指定する必要がある.
# 'B'行の削除
df.drop(index=['B'])
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
# 't'列の削除
df.drop(columns=['t'])
| player | x | y | |
|---|---|---|---|
| A | ozora | 5.0 | 10.0 |
| B | misaki | 20.0 | 1.0 |
| C | wakabayashi | 10.5 | 50.5 |
| D | hyuga | 32.5 | 2.5 |
# 't'列と'player'列の削除
df.drop(columns=['t', 'player'])
| x | y | |
|---|---|---|
| A | 5.0 | 10.0 |
| B | 20.0 | 1.0 |
| C | 10.5 | 50.5 |
| D | 32.5 | 2.5 |
4.5.2. データの並び替え#
Pandasには特定の列の値によってデータを並び替えるsort_valuesメソッドと,行ラベル(index)によってデータを並び替えるsort_indexメソッドが用意されている.
dict_data = {'t':[2, 64, 350, 600],\
'player':['ozora', 'misaki', 'wakabayashi', 'hyuga'],\
'x':[5.0, 20.0, 10.5, 32.5],
'y':[10.0, 1.0, 50.5, 2.5]}
df = pd.DataFrame(dict_data, index=[2, 0, 1, 3])
df
| t | player | x | y | |
|---|---|---|---|---|
| 2 | 2 | ozora | 5.0 | 10.0 |
| 0 | 64 | misaki | 20.0 | 1.0 |
| 1 | 350 | wakabayashi | 10.5 | 50.5 |
| 3 | 600 | hyuga | 32.5 | 2.5 |
値によるソート:sort_valuesメソッド
特定の行・列の値によってソートしたい場合はsort_valuesメソッドを用いる:
df.sort_values(['ラベル1', 'ラベル2', ...], axis=0, ascending=True)
第1引数にはソートに用いるラベル名を指定する.
ラベル名を複数指定すると,まず1つ目のラベルでソートし,その後順に2つ目以降のラベルでソートされる.
また,ソートの方向はaxis引数で指定し,特定の列でソートする場合にはaxis=0,特定の行でソートする場合にはaxis=1を指定する.
dict_data = {'half': [1, 2, 1, 2],
't':[2, 64, 350, 600],
'player':['ozora', 'misaki', 'wakabayashi', 'hyuga'],
'x':[5.0, 20.0, 10.5, 32.5],
'y':[10.0, 1.0, 50.5, 2.5]}
df = pd.DataFrame(dict_data, index=[2, 0, 1, 3])
df
| half | t | player | x | y | |
|---|---|---|---|---|---|
| 2 | 1 | 2 | ozora | 5.0 | 10.0 |
| 0 | 2 | 64 | misaki | 20.0 | 1.0 |
| 1 | 1 | 350 | wakabayashi | 10.5 | 50.5 |
| 3 | 2 | 600 | hyuga | 32.5 | 2.5 |
# 'half'列,'t'列の順にソート
df.sort_values(['half', 't'], axis=0, ascending=True)
| half | t | player | x | y | |
|---|---|---|---|---|---|
| 2 | 1 | 2 | ozora | 5.0 | 10.0 |
| 1 | 1 | 350 | wakabayashi | 10.5 | 50.5 |
| 0 | 2 | 64 | misaki | 20.0 | 1.0 |
| 3 | 2 | 600 | hyuga | 32.5 | 2.5 |
特定の行を用いてソートする場合,数値と文字列が混在する可能性が高いが,この場合はエラーになる.以下は'player'列を削除してから第2行の値でソートしている.
# 'half'列,'t'列の順にソート
df2 = df.drop(['player'], axis=1)
df2.sort_values(by=2, axis=1, ascending=True)
| half | t | x | y | |
|---|---|---|---|---|
| 2 | 1 | 2 | 5.0 | 10.0 |
| 0 | 2 | 64 | 20.0 | 1.0 |
| 1 | 1 | 350 | 10.5 | 50.5 |
| 3 | 2 | 600 | 32.5 | 2.5 |
行・列ラベルによるソート:sort_indexメソッド
上のdfは行ラベルが[2,0,1,3]という順になっている.このような場合にsort_indexメソッドを用いると,行ラベル/列ラベルによってDataFrameを辞書順に並び替えることができる:
df.sort_index(axis=0, ascending=True)
行ラベルか列ラベルかはaxis引数で指定する.並び替えの方法(昇順か降順)はascending引数に指定し,Trueの場合は昇順,Falseの場合は降順となる.
# 行ラベルの昇順でソート
df.sort_index(axis=0, ascending=True)
| half | t | player | x | y | |
|---|---|---|---|---|---|
| 0 | 2 | 64 | misaki | 20.0 | 1.0 |
| 1 | 1 | 350 | wakabayashi | 10.5 | 50.5 |
| 2 | 1 | 2 | ozora | 5.0 | 10.0 |
| 3 | 2 | 600 | hyuga | 32.5 | 2.5 |
# 行ラベルの降順でソート
df.sort_index(axis=0, ascending=False)
| half | t | player | x | y | |
|---|---|---|---|---|---|
| 3 | 2 | 600 | hyuga | 32.5 | 2.5 |
| 2 | 1 | 2 | ozora | 5.0 | 10.0 |
| 1 | 1 | 350 | wakabayashi | 10.5 | 50.5 |
| 0 | 2 | 64 | misaki | 20.0 | 1.0 |
# 列ラベルの昇順でソート
df.sort_index(axis=1, ascending=True)
| half | player | t | x | y | |
|---|---|---|---|---|---|
| 2 | 1 | ozora | 2 | 5.0 | 10.0 |
| 0 | 2 | misaki | 64 | 20.0 | 1.0 |
| 1 | 1 | wakabayashi | 350 | 10.5 | 50.5 |
| 3 | 2 | hyuga | 600 | 32.5 | 2.5 |
4.5.3. 行ラベル・列ラベルの変更#
df = pd.DataFrame(np.arange(12).reshape(4, 3),
index=[3, 0, 2, 1],
columns=['b', 'c', 'a'])
df
| b | c | a | |
|---|---|---|---|
| 3 | 0 | 1 | 2 |
| 0 | 3 | 4 | 5 |
| 2 | 6 | 7 | 8 |
| 1 | 9 | 10 | 11 |
index属性・columns属性への代入
df2 = df.copy()
df2.index = ['A', 'B', 'C', 'D']
df2
| b | c | a | |
|---|---|---|---|
| A | 0 | 1 | 2 |
| B | 3 | 4 | 5 |
| C | 6 | 7 | 8 |
| D | 9 | 10 | 11 |
df2 = df.copy()
df2.columns = [0, 1, 2]
df2
| 0 | 1 | 2 | |
|---|---|---|---|
| 3 | 0 | 1 | 2 |
| 0 | 3 | 4 | 5 |
| 2 | 6 | 7 | 8 |
| 1 | 9 | 10 | 11 |
行ラベル(index)を連番で振り直す:reset_indexメソッド
reset_indexメソッドを用いると,行ラベル(index)を0から始まる連番で振り直すことができる.
デフォルトではdrop引数が0になっており,元のindexが新たな列としてDataFrameに残る.
元のindexを削除したい場合はdrop=1を指定する.
# 元のindexを残す
df.reset_index(drop=0)
| index | b | c | a | |
|---|---|---|---|---|
| 0 | 3 | 0 | 1 | 2 |
| 1 | 0 | 3 | 4 | 5 |
| 2 | 2 | 6 | 7 | 8 |
| 3 | 1 | 9 | 10 | 11 |
# 元のindexを削除
df.reset_index(drop=1)
| b | c | a | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
| 2 | 6 | 7 | 8 |
| 3 | 9 | 10 | 11 |
(参考)指定したラベルの順に並べ替える:reindexメソッド
reindexメソッドを用いると,指定した行・列ラベルの順番にDataFrameを並べ替えることができる.
なお,単にラベルを昇順・降順に並べ替えたい場合は既に説明したsort_indexメソッドを用いた方が良い.
# 指定した行ラベルの順に並び替え
df.reindex(index=[0, 1, 2, 3])
| b | c | a | |
|---|---|---|---|
| 0 | 3 | 4 | 5 |
| 1 | 9 | 10 | 11 |
| 2 | 6 | 7 | 8 |
| 3 | 0 | 1 | 2 |
# 指定した列ラベルの順に並び替え
df.reindex(columns=['c', 'a', 'b'])
| c | a | b | |
|---|---|---|---|
| 3 | 1 | 2 | 0 |
| 0 | 4 | 5 | 3 |
| 2 | 7 | 8 | 6 |
| 1 | 10 | 11 | 9 |
# 新たなラベルの指定
df.reindex(index=[0, 1, 2, 3, 4, 5])
| b | c | a | |
|---|---|---|---|
| 0 | 3.0 | 4.0 | 5.0 |
| 1 | 9.0 | 10.0 | 11.0 |
| 2 | 6.0 | 7.0 | 8.0 |
| 3 | 0.0 | 1.0 | 2.0 |
| 4 | NaN | NaN | NaN |
| 5 | NaN | NaN | NaN |
# 新たなラベルを指定し,欠損値を穴埋め
df.reindex(index=[0, 1, 2, 3, 4, 5], fill_value=0)
| b | c | a | |
|---|---|---|---|
| 0 | 3 | 4 | 5 |
| 1 | 9 | 10 | 11 |
| 2 | 6 | 7 | 8 |
| 3 | 0 | 1 | 2 |
| 4 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 |
4.5.4. (参考)データの結合#
複数のDataFrameがあったとき,これらを結合する方法として,concat関数,merge関数,join関数が用意されている.
concat関数は縦方向と横方向に連結ができる.
一方,merge関数とjoin関数は横方向に連結する関数であり,merge関数は特定の列,join関数はindexを基準に連結する.
ここでは,concat関数だけを説明する.
concat関数
concat関数は次の形式で実行する:
pd.concat([df1, df2, ...], axis=0, join='outer')
axis引数に0を指定すると縦方向,1を指定すると横方向に連結される(デフォルトは0).
join引数は'outer'または'inner'を指定する(デフォルトは'outer').挙動は以下で説明する.
df1 = pd.DataFrame(np.arange(0, 6).reshape(2, 3),
columns=['a', 'b', 'c'])
df1
| a | b | c | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
# 列ラベルが一部異なるDataFrame
df2 = pd.DataFrame(np.arange(6, 12).reshape(2, 3),
columns=['a', 'e', 'f'])
df2
| a | e | f | |
|---|---|---|---|
| 0 | 6 | 7 | 8 |
| 1 | 9 | 10 | 11 |
# 行ラベルが一部異なるDataFrame
df3 = pd.DataFrame(np.arange(6, 12).reshape(2, 3),
columns=['d', 'e', 'f'],
index=[1, 2])
df3
| d | e | f | |
|---|---|---|---|
| 1 | 6 | 7 | 8 |
| 2 | 9 | 10 | 11 |
縦方向の連結(axis=0)
縦に連結する場合はaxis=0を指定する.列ラベル(columns)が同じ場合,そのまま縦に連結される.連結するDataFrameは2個以上でも良い.
# 縦に連結(列ラベルが同じ場合)
pd.concat([df1, df1, df1], axis=0)
| a | b | c | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
列ラベルが一部異なる場合,新たな列が追加される.
# 縦に連結(列ラベルが一部異なる場合)
pd.concat([df1, df2], axis=0)
| a | b | c | e | f | |
|---|---|---|---|---|---|
| 0 | 0 | 1.0 | 2.0 | NaN | NaN |
| 1 | 3 | 4.0 | 5.0 | NaN | NaN |
| 0 | 6 | NaN | NaN | 7.0 | 8.0 |
| 1 | 9 | NaN | NaN | 10.0 | 11.0 |
join='inner'を指定すると,ラベルが共通の列だけが残る.
# 縦に連結(列ラベルが一部異なる場合)
pd.concat([df1, df2], axis=0, join='inner')
| a | |
|---|---|
| 0 | 0 |
| 1 | 3 |
| 0 | 6 |
| 1 | 9 |
横方向の連結(axis=1)
横に連結する場合はaxis=1を指定する.行ラベル(index)が同じ場合,そのまま横に連結される.
# 横に連結(行ラベルが同じ場合)
pd.concat([df1, df1], axis=1)
| a | b | ... | b | c | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | ... | 1 | 2 |
| 1 | 3 | 4 | ... | 4 | 5 |
2 rows × 6 columns
行ラベルが一部異なる場合,新たな行が追加される
# 横に連結(行ラベルが一部異なる場合)
pd.concat([df1, df3], axis=1)
| a | b | ... | e | f | |
|---|---|---|---|---|---|
| 0 | 0.0 | 1.0 | ... | NaN | NaN |
| 1 | 3.0 | 4.0 | ... | 7.0 | 8.0 |
| 2 | NaN | NaN | ... | 10.0 | 11.0 |
3 rows × 6 columns
join='inner'を指定すると,ラベルが共通の行だけが残る.
# 横に連結(行ラベルが同じ場合)
pd.concat([df1, df3], axis=1, join='inner')
| a | b | ... | e | f | |
|---|---|---|---|---|---|
| 1 | 3 | 4 | ... | 7 | 8 |
1 rows × 6 columns
4.5.5. (参考)データの重複処理#
重複データの削除(drop_duplicatesメソッド)
pandasで重複したデータを削除するにはdrop_duplicatesメソッドを用いる.drop_duplicatesメソッドは以下のように指定する:
df.drop_duplicates(keep='first', subset=['列名1', '列名2', ...])
keep引数は重複した複数行のうち,削除しないで残す(keepする)行を指定する.デフォルトではkeep='first'となっており,重複した行のうち最初の行が残る.keep='last'とすると最後の行が残り,keep=Falseとすれば重複する全ての行が削除される.
また,デフォルトでは全ての列の値が一致しているときに重複と見なされるが,特定の列だけで判断したい場合はsubset引数に列名のリストを指定する.
dict_data = {'t':[2, 64, 64, 350, 600, 600, 600],
'player':['ozora', 'misaki', 'misaki', 'wakabayashi', 'hyuga', 'hyuga', 'hyuga'],
'x':[5.0, 20.0, 20.0, 10.5, 32.5, 32.5, 32.5],
'y':[10.0, 1.0, 1.0, 50.5, 2.5, 2.5, 2.5]}
df = pd.DataFrame(dict_data)
df
| t | player | x | y | |
|---|---|---|---|---|
| 0 | 2 | ozora | 5.0 | 10.0 |
| 1 | 64 | misaki | 20.0 | 1.0 |
| 2 | 64 | misaki | 20.0 | 1.0 |
| 3 | 350 | wakabayashi | 10.5 | 50.5 |
| 4 | 600 | hyuga | 32.5 | 2.5 |
| 5 | 600 | hyuga | 32.5 | 2.5 |
| 6 | 600 | hyuga | 32.5 | 2.5 |
# 重複する最初の行を残す
df.drop_duplicates(keep='first', subset=None)
| t | player | x | y | |
|---|---|---|---|---|
| 0 | 2 | ozora | 5.0 | 10.0 |
| 1 | 64 | misaki | 20.0 | 1.0 |
| 3 | 350 | wakabayashi | 10.5 | 50.5 |
| 4 | 600 | hyuga | 32.5 | 2.5 |
# 重複する最後の行を残す
df.drop_duplicates(keep='last', subset=None)
| t | player | x | y | |
|---|---|---|---|---|
| 0 | 2 | ozora | 5.0 | 10.0 |
| 2 | 64 | misaki | 20.0 | 1.0 |
| 3 | 350 | wakabayashi | 10.5 | 50.5 |
| 6 | 600 | hyuga | 32.5 | 2.5 |
# 重複する全ての行を削除
df.drop_duplicates(keep=False, subset=None)
| t | player | x | y | |
|---|---|---|---|---|
| 0 | 2 | ozora | 5.0 | 10.0 |
| 3 | 350 | wakabayashi | 10.5 | 50.5 |
重複データの検出(duplicatedメソッド)
重複したデータを検出するにはduplicatedメソッドを用いる.duplicatedメソッドは以下のように指定する:
df.duplicated(keep='first', subset=['列名1', '列名2', ...])
duplicatedメソッドを適用すると,重複した行をTrue,それ以外の行をFalseとするブール値のSeriesが得られる.
keep引数は重複した複数行のうち,検出しない行を指定する(重複を削除するときに残る行なのでkeep).デフォルトではkeep='first'となっており,重複した行のうち最初の行がFalseとなる.keep='last'とすると最後の行がFalseとなり,keep=Falseとすれば重複する全ての行がTrueとなる.
また,デフォルトでは全ての列の値が一致しているときに重複と見なされるが,特定の列だけで判断したい場合はsubset引数に列名のリストを指定する.
df.duplicated(keep=False, subset=None)
0 False
1 True
2 True
3 False
4 True
5 True
6 True
dtype: bool
df.duplicated(keep='first', subset=None)
0 False
1 False
2 True
3 False
4 False
5 True
6 True
dtype: bool
df.duplicated(keep='last', subset=None)
0 False
1 True
2 False
3 False
4 True
5 True
6 False
dtype: bool
df.duplicated(keep=False, subset=['t', 'player', 'x'])
0 False
1 True
2 True
3 False
4 True
5 True
6 True
dtype: bool
重複した行はブールインデックス参照によって抽出できる.
# 重複する全ての行を検出
df.loc[df.duplicated(keep=False, subset=None)]
| t | player | x | y | |
|---|---|---|---|---|
| 1 | 64 | misaki | 20.0 | 1.0 |
| 2 | 64 | misaki | 20.0 | 1.0 |
| 4 | 600 | hyuga | 32.5 | 2.5 |
| 5 | 600 | hyuga | 32.5 | 2.5 |
| 6 | 600 | hyuga | 32.5 | 2.5 |
# 重複する最初の行は検出しない
df.loc[df.duplicated(keep='first', subset=None)]
| t | player | x | y | |
|---|---|---|---|---|
| 2 | 64 | misaki | 20.0 | 1.0 |
| 5 | 600 | hyuga | 32.5 | 2.5 |
| 6 | 600 | hyuga | 32.5 | 2.5 |
# 重複する最後の行は検出しない
df.loc[df.duplicated(keep='last', subset=None)]
| t | player | x | y | |
|---|---|---|---|---|
| 1 | 64 | misaki | 20.0 | 1.0 |
| 4 | 600 | hyuga | 32.5 | 2.5 |
| 5 | 600 | hyuga | 32.5 | 2.5 |
4.6. レポート問題#
次のcsvファイルをダウンロードし,作業フォルダ(例えばOneDrive/sport_data/4_pandas)に移動せよ:player_all.csv
このファイルには,2017年度にヨーロッパリーグ(イングランド,フランス,ドイツ,イタリア,スペイン)に所属していた選手のデータが保存されている.
※ 本データはPappalardoデータセットを加工したものである(詳細はイベントデータの解析).
player_all.csvファイルをdfに読み込め
# 解答欄
dfの先頭から2行を表示せよ
# 解答欄
肥満度を表す指標としてBMIが知られている.BMIは身長と体重を用いて以下で定義される: $\( \mathrm{BMI} = \frac{体重 [kg]}{(身長 [m])^2} \)$
身長(
height)の単位をcmからmに変換せよ.身長(
height)と体重(weight)からBMIを求め,BMI列を作成せよ.BMIが18.5未満の選手を抽出せよ.
※ この選手はRekeem Jordan Harper選手である.
※ 日本肥満学会の基準では,BMIが18.5未満の場合を痩せ型と定義している.
# 'height'の単位をcm->m
# BMIを求めて'BMI'列を作成
# BMIが18.5未満の選手を抽出
ポジション(
role)ごとに,身長,体重,BMIの平均値を計算せよ.
# ディフェンダー('DF')
# ミッドフィルダー('MF')
# フォワード('FW')
# キーパー('GK')