2022年度レポート
Contents
2022年度レポート#
レポートの諸注意#
回答方法
プログラムはコードセル(複数のセルでもよい)に記述する
問題の回答および説明はマークダウンセルに記述する
提出方法
このipynbファイルをhtml形式でエクスポートする
File -> Export Notebook As -> HTMLをクリック
自分の分かりやすいフォルダに保存する
htmlファイルをポータルのオンライン授業から提出する
ポータルサイトのオンライン授業からレポート提出場所を開く
1.で保存したhtmlファイルをアップロードする
※ ファイル名は「学籍番号_氏名.html」とすること
提出締切
7/31(日),23:59
評価基準
F評価
レポートに著しい不備がある/未提出
C評価
レポートを期限内に提出し,基礎知識に関する問題がほとんどできている
B評価
上に加え,NumPy,Pandas,Matplotlibに関する問題の一部ができている
A評価
上に加え,NumPy,Pandas,Matplotlibに関する問題がほとんどできている
S評価
上に加え,実践編に関する課題に答えている
来年度成塚のゼミを志望する場合はここまでできることが望ましい
基礎知識に関する問題#
新しいマークダウンセルを下に追加し,セル内に好きな文章を記述せよ.
これは解答例です.
絶対パスと相対パスについて自分の言葉で説明せよ
次の講義資料を参照:2.4.4 絶対パスと相対パス
Windowsにおいて,コピーしたパスをそのまま貼り付けて使用すると,python側でエラーが出る.この原因と回避する方法を自分の言葉で説明せよ
次の講義資料を参照:2.4.3 WindowsのPythonでパスを指定する際の注意
スポーツデータ分析において,Pythonを用いるメリットを自分の言葉で説明せよ
次の講義資料を参照:1.1.4 Pythonを用いる理由
※ ここに書かれているのはあくまでも一例
スポーツデータ分析において,NumPy,Pandas,Matplotlibを用いるメリットを自分の言葉で説明せよ
次の講義資料を参照:3.1 Numpyとは?,4.1.2 PandasとNumPyの違い
Matplotlibについては,NumPyやPandasとの連携がしやすい,対話的に実行できる,色やレイアウトを細かく調整できる,など(あくまでも一例).
NumPyとPandasの違いを自分の言葉で説明せよ
次の講義資料を参照:4.1.2 PandasとNumPyの違い
モジュールをインポートする意味を自分の言葉で説明せよ
公式ドキュメントなどを参照
osモジュールをインポートせよ
import os
os.chdirを用いてカレントディレクトリを適当な作業フォルダに変更せよ
os.chdir(r'/Users/narizuka/work/document/lecture/rissho/sport_programming/sport_data')
NumPyを
np,Pandasをpdという名前でインポートせよ
import numpy as np
import pandas as pd
matplotlib.pyplotを
pltという名前でインポートせよ
import matplotlib.pyplot as plt
レポートを期限内に指定された方法で提出せよ
『※ ファイル名は「学籍番号_氏名.html」とすること』を守ること
ファイルの拡張子を手動で変更するのはNG
自分のPCで開けないファイルは他の人も開けないので,提出前に確認すること
NumPyに関する問題#
問題A
以下のように,母平均5,母標準偏差0.5の正規分布に従うデータから100個を抽出した.
np.random.seed(seed=33)
x = np.random.normal(5, 0.5, 100)
x
array([4.84057325, 4.19850972, 4.23239106, 4.71479955, 4.89163585,
5.12743715, 4.92527503, 6.00539129, 4.95160792, 5.21110083,
4.88726922, 4.68102845, 4.99185685, 5.52210839, 4.45755984,
3.89703759, 4.5243905 , 5.41648659, 4.49989592, 5.17173137,
5.77301513, 5.34504047, 3.97707332, 5.16723341, 4.67927066,
4.88875163, 4.3848128 , 5.10292412, 5.4106857 , 4.75310981,
4.29560324, 4.39183809, 5.86714953, 4.89660507, 4.63340571,
5.38708145, 4.61131189, 4.79268246, 4.4271794 , 5.16252025,
5.00029714, 5.70929402, 4.92558719, 4.69686504, 4.40709941,
5.22775211, 4.58117753, 4.92651928, 4.65882514, 5.74383482,
4.45264472, 4.17264656, 4.98807898, 4.81813125, 4.75852844,
5.36978853, 5.30562592, 5.24590114, 5.89646193, 4.65813143,
5.52705652, 4.69221878, 5.21872127, 3.5953027 , 4.67321994,
5.26389329, 5.46636086, 4.94430432, 4.43964135, 5.49556808,
5.81539818, 4.049955 , 5.03115795, 5.23999877, 5.1898046 ,
4.24387751, 5.14450994, 5.04776224, 4.85358943, 5.4282912 ,
5.46673651, 4.78947748, 5.79521476, 4.46809972, 6.05244222,
4.45475285, 5.74226071, 4.4553855 , 5.30221602, 5.47090936,
4.68992847, 5.40743263, 4.54997998, 4.75979531, 5.11512886,
5.09761752, 5.2679194 , 5.34214967, 6.41063966, 5.45825179])
このデータに対し,np.mean関数とnp.std関数を用いて標本平均と標本標準偏差を求めると以下のようになった.
np.mean(x)
4.980955414556336
np.std(x)
0.5156253322316987
np.mean関数とnp.average関数を使わずにxの標本平均を求め,上の結果と一致することを確かめよ(NumPyの他の関数は用いても良い). ただし,データ\(x = (x_{1}, x_{2}, \ldots, x_{n})\)に対して,標本平均\(\bar{x}\)は以下で定義される:
np.sum(x)/x.size
4.980955414556336
np.std関数とnp.var関数を使わずにxの標本標準偏差を求め,上の結果と一致することを確かめよ(NumPyの他の関数は用いても良い). ただし,データ\(x = (x_{1}, x_{2}, \ldots, x_{n})\)に対して,標本標準偏差\(\bar{\sigma}\)は以下で定義される:
np.sqrt(np.sum((x-np.mean(x))**2)/x.size)
0.5156253322316987
問題B
次のcsvファイルをダウンロードせよ:player_England.csv
このファイルには,2017年度にイングランド・プレミアリーグに所属していた選手の選手ID,身長,体重のデータが保存されている.
ただし,身長の単位はcm,体重の単位はkgである.
※ 本データはPappalardoデータセットを加工したものである(詳細はイベントデータの解析).
以下を適当に修正し,ダウンロードしたファイルをNumPy配列
Dに読み込め:
# csvファイルのパスを指定する
D = np.loadtxt('./report/player_England.csv', delimiter=',', dtype='int')
D
array([[ 3319, 180, 76],
[ -1, 1000, 1000],
[ 3560, 179, 72],
...,
[357712, 183, 92],
[386197, 175, 71],
[412919, 190, 76]])
配列Dは第0列に選手ID,第1列に身長,第2列に体重が格納されている.
例えば,Dの第0行目を見ると,選手IDが3319で身長180cm,体重76kgであることが分かる.
このデータに対し,以下の問いに答えよ.
選手IDが-1となっている要素はダミーデータである.
Dからダミーデータを削除し,改めて配列Dとせよ.
D = D[D[:, 0]!=-1]
データに含まれる選手数を調べよ.
len(D)
441
選手IDが703の選手の身長と体重を調べよ.
※ この選手は吉田麻也選手である.2017年時点の体重と現在の体重を比較してみよ.
D[D[:, 0]==703]
array([[703, 189, 78]])
配列Dから選手ID,身長,体重のデータを抽出し,それぞれI, H, Wという配列に格納せよ.
I = D[:, 0]
H = D[:, 1]
W = D[:, 2]
以下の方法により,身長の最小値,最大値を求めよ
Hを昇順(小→大)に並び替え,先頭と末尾の要素を抽出するnp.min,np.max関数を用いる
# Hを昇順に並び替えて先頭と末尾の要素を抽出
np.sort(H)[0], np.sort(H)[-1]
(163, 201)
# np.min, np.maxを用いる
np.min(H), np.max(H)
(163, 201)
肥満度を表す指標としてBMIが知られている.BMIは身長と体重を用いて以下で定義される: $\( \mathrm{BMI} = \frac{体重 [kg]}{(身長 [m])^2} \)$
身長の単位をcmからmに変換し,
H2に格納せよ.配列
WとH2からBMIを求め,BMIという配列に格納せよ.BMIが18.5未満の選手が1人いる.この選手のIDを調べよ.
※ この選手はRekeem Jordan Harper選手である.
※ 日本肥満学会の基準では,BMIが18.5未満の場合を痩せ型と定義している.
# Hの単位をcm -> m
H2 = H/100
# BMIを求める
BMI = W/(H2**2)
# BMIが18.5未満を抽出
D[BMI < 18.5]
array([[447254, 188, 64]])
Pandasに関する問題#
# 表示設定
pd.set_option('display.max_columns', 5) # 表示する列数の上限
次のcsvファイルをダウンロードせよ:player_all.csv
このファイルには,2017年度にヨーロッパリーグ(イングランド,フランス,ドイツ,イタリア,スペイン)に所属していた選手のデータが保存されている.
※ 本データはPappalardoデータセットを加工したものである(詳細はイベントデータの解析).
以下を適当に修正し,
player_all.csvファイルをdfに読み込め
df = pd.read_csv('./report/player_all.csv', header=0, index_col='player_id', na_values=0)
df
| name | team_id | ... | birthday | league | |
|---|---|---|---|---|---|
| player_id | |||||
| 3319 | M_Özil | 1609 | ... | 1988/10/15 | England |
| 3560 | Nach_Monreal | 1609 | ... | 1986/02/26 | England |
| 7855 | L_Koscielny | 1609 | ... | 1985/09/10 | England |
| 7870 | A_Ramsey | 1609 | ... | 1990/12/26 | England |
| 7882 | P_Čech | 1609 | ... | 1982/05/20 | England |
| ... | ... | ... | ... | ... | ... |
| 266885 | M_Olunga | 756 | ... | 1994/03/26 | Spain |
| 282448 | Alei_García | 756 | ... | 1997/06/28 | Spain |
| 366374 | K_Soni | 756 | ... | 1998/04/17 | Spain |
| 443324 | Dougla_Luiz | 756 | ... | 1998/05/09 | Spain |
| 508686 | M_Lizak | 756 | ... | 1996/07/15 | Spain |
2439 rows × 10 columns
dfの先頭から2行を表示せよ
df.head(2)
| name | team_id | ... | birthday | league | |
|---|---|---|---|---|---|
| player_id | |||||
| 3319 | M_Özil | 1609 | ... | 1988/10/15 | England |
| 3560 | Nach_Monreal | 1609 | ... | 1986/02/26 | England |
2 rows × 10 columns
肥満度を表す指標としてBMIが知られている.BMIは身長と体重を用いて以下で定義される: $\( \mathrm{BMI} = \frac{体重 [kg]}{(身長 [m])^2} \)$
身長(
height)の単位をcmからmに変換せよ.身長(
height)と体重(weight)からBMIを求め,BMI列を作成せよ.BMIが18.5未満の選手を抽出せよ.
※ この選手はRekeem Jordan Harper選手である.
※ 日本肥満学会の基準では,BMIが18.5未満の場合を痩せ型と定義している.
# 'height'の単位をcm->m
df['height']/100
player_id
3319 1.80
3560 1.79
7855 1.86
7870 1.83
7882 1.96
...
266885 1.88
282448 1.73
366374 1.82
443324 1.78
508686 1.92
Name: height, Length: 2439, dtype: float64
# BMIを求めて'BMI'列を作成
df['BMI'] = df['weight']/(df['height']/100)**2
# BMIが18.5未満の選手を抽出
df.loc[df['BMI'] < 18.5]
| name | team_id | ... | league | BMI | |
|---|---|---|---|---|---|
| player_id | |||||
| 447254 | R_Harper | 1627 | ... | England | 18.107741 |
1 rows × 11 columns
ポジション(
role)ごとに,身長,体重,BMIの平均値を計算せよ.
df['role'].unique()
array(['MD', 'DF', 'GK', 'FW'], dtype=object)
# ディフェンダー('DF')
df.loc[df['role']=='DF', ['height', 'weight', 'BMI']].mean()
height 183.554612
weight 77.388078
BMI 22.951412
dtype: float64
# ミッドフィルダー('MF')
df.loc[df['role']=='MD', ['height', 'weight', 'BMI']].mean()
height 179.708038
weight 73.494675
BMI 22.744956
dtype: float64
# フォワード('FW')
df.loc[df['role']=='FW', ['height', 'weight', 'BMI']].mean()
height 181.384929
weight 75.699387
BMI 22.983658
dtype: float64
# キーパー('GK')
df.loc[df['role']=='GK', ['height', 'weight', 'BMI']].mean()
height 189.635338
weight 83.441509
BMI 23.194241
dtype: float64
※ groupbyを用いると1行で書ける
df.groupby('role').mean()
| team_id | height | weight | BMI | |
|---|---|---|---|---|
| role | ||||
| DF | 2540.050602 | 183.554612 | 77.388078 | 22.951412 |
| FW | 2664.815416 | 181.384929 | 75.699387 | 22.983658 |
| GK | 2689.432331 | 189.635338 | 83.441509 | 23.194241 |
| MD | 2584.602353 | 179.708038 | 73.494675 | 22.744956 |
Matplotlibに関する問題#
4.で用いたplayer_all.csvについて,次の問いに答えよ.
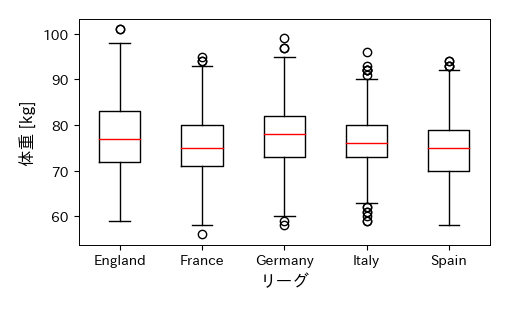
問題A:体重の箱ひげ図
Englandリーグに所属する選手の体重のデータから欠損値を除外したデータは以下で取得できる.data1 = df.loc[df['league']=='England', 'weight'].dropna()
全てのリーグに対して同様のデータを求め,以下のようなリストを作成せよ
D = [data1, data2, ...]
方法1
data1 = df.loc[df['league']=='England', 'weight'].dropna()
data2 = df.loc[df['league']=='France', 'weight'].dropna()
data3 = df.loc[df['league']=='Germany', 'weight'].dropna()
data4 = df.loc[df['league']=='Italy', 'weight'].dropna()
data5 = df.loc[df['league']=='Spain', 'weight'].dropna()
D = [data1, data2, data3, data3, data4, data5]
方法2(for文)
D = []
for l in df['league'].unique():
D.append(df.loc[df['league']==l, 'weight'].dropna())
方法3(リスト内包表記)
D = [df.loc[df['league']==l, 'weight'].dropna() for l in df['league'].unique()]
リスト
Dを用いて,体重の箱ひげ図をリーグ別に作成せよ.また,グラフを分かりやすく装飾せよ.
※ 講義資料のコードをほぼそのまま利用できます
# 箱ひげ図のプロット
fig, ax = plt.subplots(figsize=(5, 3))
ret = ax.boxplot(D, whis=1.5, widths=0.5, vert=1)
# 横軸の目盛りラベル
ax.set_xticklabels(df['league'].unique())
# 軸のラベル
ax.set_xlabel('リーグ', fontsize=12)
ax.set_ylabel('体重 [kg]', fontsize=12)
Text(0, 0.5, '体重 [kg]')
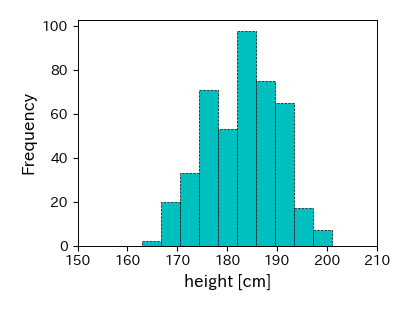
問題B:身長のヒストグラム
Englandリーグに所属する選手の身長のヒストグラムを以下の条件で作成せよ:横軸のラベル:
height [cm]縦軸のラベル:
Frequency階級の数:10
その他の装飾は自由
※ 講義資料のコードをほぼそのまま利用できます
H_e = df.loc[df['league']=='England', 'height'].dropna()
fig, ax = plt.subplots(figsize=(4, 3))
ret = ax.hist(H_e,
bins=10,
histtype='bar', # ヒストグラムのスタイルを棒グラフに
color='c', # バーの色をシアンに
edgecolor='k', # バーの枠線の色を黒に
linewidth=0.5, # バーの枠線の太さを1に
linestyle='--', # 枠線を点線に
)
# 軸のラベル
ax.set_xlabel('height [cm]', fontsize=12)
ax.set_ylabel('Frequency', fontsize=12)
ax.set_xlim(150, 210)
(150.0, 210.0)
実践編に関する課題#
授業内で扱ったデータをPythonを用いて自由に解析し,解析結果をまとめよ.
解析内容は些細なことでも良い
既に知られていることでも良い