# (必須)モジュールのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 表示設定
np.set_printoptions(suppress=True, precision=3)
pd.set_option('display.precision', 3) # 小数点以下の表示桁
pd.set_option('display.max_rows', 50) # 表示する行数の上限
pd.set_option('display.max_columns', 10) # 表示する列数の上限
%precision 3
'%.3f'
本章は以下の文献とウェブサイトを参考にしています:
株式会社ロンバート・増田秀人,現場で使える!pandsデータ前処理入門,翔泳社,2020.
Wes McKinney, Pythonによるデータ分析入門,オライリー,2018
Jake VanderPlas, Pythonデータサイエンスハンドブック,オライリー,2018
4. Pandasの基礎#
4.1. Pandasとは?#
4.1.1. Pandasのインポート#
Pandas(パンダス)はpdという名前でインポートするのが慣例である:
import pandas as pd
4.1.2. PandasとNumPyの違い#
前章では,NumPyを用いて多次元配列を扱う方法を解説した.NumPyでは数値データの処理を非常に高速に実現することができた.一方,Pandas(パンダス)も基本的には多次元配列を扱うためのライブラリであり,PandasとNumPyを相互に変換することもできる.しかし,PandasにはNumPyと異なる以下のような特徴がある:
行と列にラベル(行と列の名前)が付与される
列ごとに異なる型のデータ(数値や文字列)を混在させることができる
欠損値の処理やデータの整形のための機能を備えている
様々な形式のデータに対するファイル入出力機能を備えている
データの可視化機能を備えている
スポーツデータには文字列や数値など様々な型のデータが含まれるため,こうしたデータを整形したり集約したりするにはNumPyよりもPandasを用いた方が便利である.
例えば,以下は,典型的なサッカーのイベントデータをPandasのDataFrameという形式(後述)で表したものである.
pd.DataFrame({'t':[2, 64, 350, 600],
'player':['ozora', 'misaki', 'wakabayashi', 'hyuga'],
'position': ['MF', 'MF', 'GK', 'FW'],
'x':[5.0, 20.0, 10.5, 32.5],
'y':[10.0, 1.0, 50.5, 2.5]},
index = ['A', 'B', 'C', 'D'])
| t | player | position | x | y | |
|---|---|---|---|---|---|
| A | 2 | ozora | MF | 5.0 | 10.0 |
| B | 64 | misaki | MF | 20.0 | 1.0 |
| C | 350 | wakabayashi | GK | 10.5 | 50.5 |
| D | 600 | hyuga | FW | 32.5 | 2.5 |
このデータは1つの行が1イベントに対応しており,AからDまでの行ラベル(=index)が付与されている.
また,各列には時刻(整数型),選手名(文字列型),位置座標(浮動小数点型),など異なるデータ型が混在しており,それぞれに't','player'",'position','x','y'という列ラベル(=columns)が付与されている.
このデータを処理するためには,NumPyではなくPandasを用いた方が便利そうだと分かるだろう.
なお,ラベルの付いていない巨大な数値データを扱いたい場合や3次元以上の数値データを扱いたい場合など,NumPyを用いた方が良い場面ももちろんある.
また,データの可視化はPandasでもできるが,より多機能なMatplotlibを用いることを推奨する.
4.2. DataFrameオブジェクト#
NumPyではデータをndarrayオブジェクト(NumPy配列)に格納し,様々な処理を行なった. Pandasでも2次元のデータを扱うための専用のオブジェクトDataFrameが用意されている. DataFrameは(Excelのような)テーブル形式の構造を持ち,以下の特徴がある:
各列には数値や文字列など異なる型を持たせることができる.
行と列にはラベルが付与されており,行方向のラベルをindex(インデックス),列方向のラベルをcolumns(カラム)と呼ぶ.
indexとcolumnsには数値や文字列を用いて任意のラベルを与えることができる.
行と列にはNumPy配列と同じ行番号・列番号も付与されており,行番号が増える方向を
axis=0,列番号が増える方向をaxis=1と呼ぶ.
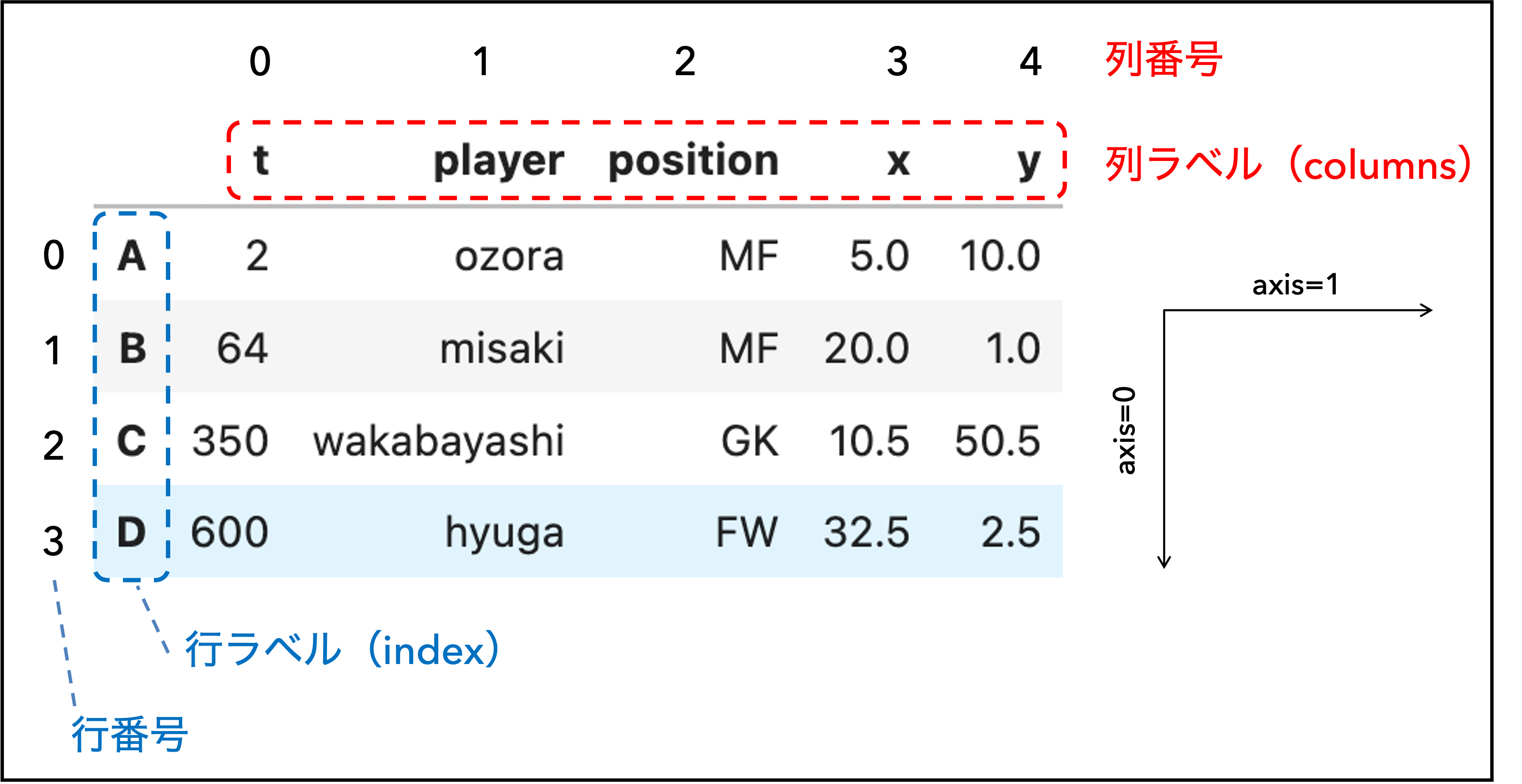
図 4.1 DataFrameの例#
4.2.1. DataFrameの生成#
DataFrameを生成するには,以下のようにpd.DataFrame関数を用いる:
pd.DataFrame(data, index=[0, 1], columns=['A', 'B', 'C'])
第1引数dataにはリスト,NumPy配列,辞書などを指定できる.
また,オプションとして,行ラベルを表すindexと列ラベルを表すcolumnsを指定することができる.
リスト・NumPy配列の変換
# リストの変換
pd.DataFrame([[1,2,3], [4,5,6]],
index=[0, 1],
columns=['A', 'B', 'C'])
| A | B | C | |
|---|---|---|---|
| 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 |
# NumPy配列の変換
pd.DataFrame(np.full([2, 3], 5),
index=[0, 1],
columns=['A', 'B', 'C'])
| A | B | C | |
|---|---|---|---|
| 0 | 5 | 5 | 5 |
| 1 | 5 | 5 | 5 |
辞書の変換
第1引数に辞書を指定すると,辞書のkeyが列ラベルcolumnsとなる.
行ラベルindexはオプションとして指定する.
# 辞書データ
dict_data = {'t':[2, 64, 350, 600],
'player':['ozora', 'misaki', 'wakabayashi', 'hyuga'],
'x':[5.0, 20.0, 10.5, 32.5],
'y':[10.0, 1.0, 50.5, 2.5]}
dict_data
{'t': [2, 64, 350, 600],
'player': ['ozora', 'misaki', 'wakabayashi', 'hyuga'],
'x': [5.000, 20.000, 10.500, 32.500],
'y': [10.000, 1.000, 50.500, 2.500]}
# 辞書による生成
pd.DataFrame(dict_data, index=['A', 'B', 'C', 'D'])
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
4.2.2. 欠損値について#
データが何らかの事情で欠落している箇所を欠損値と呼ぶ.
Pandasにおいて,欠損値はNaNと表示される('Not a Number'の略).
Pandasでは,空白値の他,pythonの組み込み定数であるNoneやmath.nan,np.nanは全て欠損値として扱われる.
※ 無限大を表すinfはデフォルトでは欠損値として扱われない.
# 欠損値を含むDataFrameの作成
import math
df = pd.DataFrame([[1., None, np.nan], [math.nan, 2, 3]])
df
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1.0 | NaN | NaN |
| 1 | NaN | 2.0 | 3.0 |
4.2.3. DataFrameのファイル入出力#
Pandasでデータ分析を行う場合,外部のファイルから直接データを読み込んだり,整形したデータを改めてファイルに保存することが多い.特に,データ分析でよく用いられるのがcsv形式のファイルである.csvとはカンマで区切られたテキストファイルを指す略称で,Excelで編集することもできる.
csvファイルに保存する
まず,DataFrameをcsvファイルに保存するには,to_csvメソッドを用いる:
df.to_csv('***.csv', option)
第1引数には保存先ファイルのパスを指定し,第2引数以降にオプションを指定する.
# DataFrameを生成する
df = pd.DataFrame({'t':[2, 64, 350, 600],
'player':['ozora', 'misaki', 'wakabayashi', 'hyuga'],
'x':[5.0, 20.0, 10.5, 32.5],
'y':[10.0, 1.0, 50.5, 2.5]},
index=['A', 'B', 'C', 'D'])
# 相対パスを指定してカレントディレクトリに保存する
df.to_csv('./df_sample.csv', # ipynbファイルと同じフォルダに保存
header=True, # 列ラベルを出力する
index=True, # 行ラベルを出力する
encoding='utf-8', # 文字コードを指定する
columns=df.columns # 出力する列を指定する
)
csvファイルをPCから読み込む
次に,csvファイルを読み込むにはpd.read_csv関数を用いる:
pd.read_csv('***.csv', option)
第1引数にcsvファイルのパスを指定し,第2引数以降にoptionを指定する.
# 相対パスを指定してcsvファイルをDataFrameに読み込む
df = pd.read_csv('./df_sample.csv',
header=0, # 第0行目を列ラベルとする
index_col=0, # 第0列目を行ラベルとする
usecols=None, # 読み込む列を指定する
na_values=None # 欠損値として認識する文字列を指定する
)
df
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
csvファイルをURLから読み込む
pd.read_csv関数にURLを指定してcsvファイルを読み込むこともできる:
df = pd.read_csv(url, option)
第1引数にURLを指定し,第2引数以降にoptionを指定する.
df = pd.read_csv('https://tnarizuka.github.io/sports_data_programming/chap_4/df_sample.csv', index_col=0)
df
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
4.2.4. DataFrameの属性#
DataFrameに対して,df.属性名とすることで,dfの様々な情報を取得できる.
# DataFrameの読み込み
df = pd.read_csv('./df_sample.csv', header=0, index_col=0)
df
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
NumPy配列の取得:values属性
values属性を用いると,値をNumPy配列として取り出すことができる.
※ 複数の型が混在するDataFrameの場合,取り出したNumPy配列はobject型という特殊な型になる.
# 値をNumPy配列として取り出す
df.values
array([[2, 'ozora', 5.0, 10.0],
[64, 'misaki', 20.0, 1.0],
[350, 'wakabayashi', 10.5, 50.5],
[600, 'hyuga', 32.5, 2.5]], dtype=object)
行・列ラベルの取得:index属性,columns属性
DataFrameの行ラベルと列ラベルはindex属性とcolumns属性で抽出できる.
# 行ラベル
df.index
Index(['A', 'B', 'C', 'D'], dtype='object')
# 列ラベル
df.columns
Index(['t', 'player', 'x', 'y'], dtype='object')
その他の属性
# DataFrameの要素数
df.size
16
# DataFrameの形状
df.shape
(4, 4)
# 各列のデータ型
df.dtypes
t int64
player object
x float64
y float64
dtype: object
4.3. DataFrameの参照#
DataFrameも,NumPy配列のように配列の一部分を参照することができる. ただし,DataFrameには行番号・列番号の他に,行ラベル・列ラベルが存在するため,以下のようにこれらを区別する:
行・列番号によって参照する方法:
iloc属性(NumPyのインデックス参照と同じ)行・列ラベルによって参照する方法:
loc属性,角括弧[]
# csvファイルをDataFrameに読み込む
df = pd.read_csv('./df_sample.csv', header=0, index_col=0)
df
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
4.3.1. 行・列番号による参照:iloc属性#
DataFrameを行番号と列番号によって参照するには以下のようにiloc属性を用いる:
df.iloc[行番号, 列番号]
これは,基本的にNumPyのインデックス参照と同じ機能であり,スライスにも対応している.
# 第1行の参照(列番号は省略可)
df.iloc[1]
t 64
player misaki
x 20.0
y 1.0
Name: B, dtype: object
# 第1列の参照(行番号に:を指定)
df.iloc[:, 1]
A ozora
B misaki
C wakabayashi
D hyuga
Name: player, dtype: object
# 第1~3行のスライス(列番号は省略)
df.iloc[1:4]
| t | player | x | y | |
|---|---|---|---|---|
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
# 第1~2列のスライス(行番号に:を指定)
df.iloc[:, 1:3]
| player | x | |
|---|---|---|
| A | ozora | 5.0 |
| B | misaki | 20.0 |
| C | wakabayashi | 10.5 |
| D | hyuga | 32.5 |
複数の行番号,列番号はリストで指定する(角括弧[]を二重にする).
# 第1行と3行の参照
df.iloc[[1, 3]]
| t | player | x | y | |
|---|---|---|---|---|
| B | 64 | misaki | 20.0 | 1.0 |
| D | 600 | hyuga | 32.5 | 2.5 |
# 第1列と3列の参照
df.iloc[:, [1, 3]]
| player | y | |
|---|---|---|
| A | ozora | 10.0 |
| B | misaki | 1.0 |
| C | wakabayashi | 50.5 |
| D | hyuga | 2.5 |
# 第0列〜2列の参照(スライス)
df.iloc[:, :3]
| t | player | x | |
|---|---|---|---|
| A | 2 | ozora | 5.0 |
| B | 64 | misaki | 20.0 |
| C | 350 | wakabayashi | 10.5 |
| D | 600 | hyuga | 32.5 |
4.3.2. 行・列ラベルによる参照:loc属性#
行ラベルと列ラベルによって値を参照するには以下のようにloc属性を用いる:
df.loc['行ラベル', '列ラベル']
これはNumPyにはないPandas特有の方法である. なお,特定の行を参照する場合,列ラベルは省略できる.
df
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
# 'A'行を参照(列ラベルは省略)
df.loc['A']
t 2
player ozora
x 5.0
y 10.0
Name: A, dtype: object
# 複数の行はリストで指定する(角括弧を二重にする)
df.loc[['A', 'C']]
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
# 複数の列を参照(行ラベルに:を指定する)
df.loc[:, ['x', 'y']]
| x | y | |
|---|---|---|
| A | 5.0 | 10.0 |
| B | 20.0 | 1.0 |
| C | 10.5 | 50.5 |
| D | 32.5 | 2.5 |
# 行ラベルが'A',列ラベルが't'の要素を参照
df.loc['A', 't']
np.int64(2)
# 複数の行ラベルと列ラベルの指定
df.loc[['A', 'C'], ['x', 'y']]
| x | y | |
|---|---|---|
| A | 5.0 | 10.0 |
| C | 10.5 | 50.5 |
4.3.3. 角括弧[]による列の抽出#
角括弧を使ってdf['t']とすることで't'というラベルの列を取り出すことができる.
ただし,列ラベルを用いて列を抽出する場合に限る.
# 't'列の参照(df.loc[:, 't']と同じ)
df['t']
A 2
B 64
C 350
D 600
Name: t, dtype: int64
複数の列ラベルをリストで指定すると,複数の列を取り出すことができる.
# 'x'と'y'列の参照(df.loc[:, ['x', 'y']]と同じ)
df[['x', 'y']]
| x | y | |
|---|---|---|
| A | 5.0 | 10.0 |
| B | 20.0 | 1.0 |
| C | 10.5 | 50.5 |
| D | 32.5 | 2.5 |
先頭または末尾から数行だけ抽出:headメソッド,tailメソッド
DataFrame
dfの先頭からn行だけ抽出したい場合はdf.head(n)とする.DataFrame
dfの末尾からn行だけ抽出したい場合はdf.tail(n)とする.
# 先頭から2行だけ抽出
df.head(2)
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
# 末尾から2行だけ抽出
df.tail(2)
| t | player | x | y | |
|---|---|---|---|---|
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
4.3.4. 演習問題#
次のcsvファイルをダウンロードし,カレントディレクトリに保存せよ:player_all.csv
このファイルには,2017年度にヨーロッパリーグ(イングランド,フランス,ドイツ,イタリア,スペイン)に所属していた選手のデータが保存されている.
※ 本データはPappalardo-Wyscoutデータセットを加工したものである(詳細はPappalardo-Wyscoutデータセット).
ダウンロードしたcsvファイルをdfに読み込め.
ただし,以下のオプションを指定せよ:
header=0:最初の行を列ラベルに設定index_col='player_id':選手IDを行ラベル(index)に設定na_values=0:値が0の要素を欠損値NaNで置き換える
# 解答欄
df =
以下はplayer_all.csvの保存先のurlである:
url = 'https://tnarizuka.github.io/sports_data_programming/chap_4/player_all.csv'
このcsvファイルをurlからdfに読み込め.ただし,同様のオプションを指定せよ.
# 解答欄
df =
DataFrameの先頭2行を取得せよ
# 解答欄
DataFrameの末尾2行を取得せよ
# 解答欄
index(行ラベル)を取得せよ
# 解答欄
columns(列ラベル)を取得せよ
# 解答欄
iloc属性を用いて行番号が114の行を抽出せよ
# 解答欄
iloc属性を用いて行番号が1416~1936までの行を抽出せよ
※ これはイタリアリーグのデータである
# 解答欄
iloc属性を用いて列番号が4の列を抽出せよ
# 解答欄
iloc属性を用いて列番号が4以上の列を抽出せよ
# 解答欄
角括弧[]を用いてweight列を抽出せよ
# 解答欄
角括弧[]を用いてnationality列を抽出せよ
# 解答欄
角括弧[]を用いてteam_id列,height列,weight列を抽出せよ
※ これがNumPyのレポート問題で扱ったデータである.
# 解答欄
loc属性を用いてindex(行ラベル)が703の行を抽出せよ
# 解答欄
loc属性を用いてweight列を抽出せよ
# 解答欄
loc属性を用いてindex(行ラベル)が61941,8747,283062でcolumns(列ラベル)がname, heightの要素を抽出せよ
※ これは身長2m以上の選手のデータである
# 解答欄
loc属性を用いてindex(行ラベル)が703でcolumns(列ラベル)がname,weight,heightの要素を抽出せよ
# 解答欄
index(行ラベル)が以下の番号の選手は全て日本人である:
94764, 703, 14763, 94695, 94831, 254649, 14816, 14749, 391606, 94650, 14929, 365880, 14836, 94828
これらの選手を以下の方法で抽出せよ.
# 上のindexの順番で抽出
# 上のindexの順番で`name`列だけを抽出
# 上のindexの順番で`name`, `height`, `weight`列を抽出
# indexを昇順に並び替えた上で抽出
4.4. DataFrameの条件付き抽出#
DataFrameからある条件を満たす行や列を抽出する方法として,ブールインデックス参照がある.
※ この他にもwhereメソッド,queryメソッドなどがあるがここでは扱わない
df = pd.read_csv('./df_sample.csv', header=0, index_col=0)
df
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
4.4.1. ブールインデックスの取得#
PandasのDataFrameでも,NumPyと同様のブールインデックス参照が可能である.
NumPyと同様に==, >, <, %などの比較演算子を用いると,ブールインデックス配列(SeriesまたはDataFrame)を自動的に取得することができる.
# 't'列の値が64
df['t']==64
A False
B True
C False
D False
Name: t, dtype: bool
# 't'列の値が64より大きい
df['t']>64
A False
B False
C True
D True
Name: t, dtype: bool
# 'x'列の値が'y'列の値より大きい
df['x'] > df['y']
A False
B True
C False
D True
dtype: bool
条件が複数ある場合は(条件1) & (条件2)や(条件1)|(条件2)のように各条件を()で囲む(and, or, notは使えない)
# 't'列が64より大きくかつ'player'列が'hyuga'
(df['t']>64) & (df['player'] == 'hyuga')
A False
B False
C False
D True
dtype: bool
# 'player'列が'misaki'または'hyuga'
(df['player']=='misaki') | (df['player']=='hyuga')
A False
B True
C False
D True
Name: player, dtype: bool
ある条件の否定は~条件で実現できる.この表記は条件が多い場合に役立つ.
# 't'列が64でない(df['t']!=64と同じ)
~(df['t']==64)
A True
B False
C True
D True
Name: t, dtype: bool
4.4.2. ブールインデックス参照#
loc属性を用いた参照において,行ラベルの部分に条件を指定すると,条件を満たす行だけを抽出できる.
このとき,条件の次に列ラベルを指定すると,条件を満たす特定の列だけを抽出できる.
df.loc[条件, ['列ラベル1', '列ラベル2']]
# 't'列の値が64の行
df.loc[df['t']==64]
| t | player | x | y | |
|---|---|---|---|---|
| B | 64 | misaki | 20.0 | 1.0 |
# 't'列の値が64の行で,'x','y'列のみ抽出
df.loc[df['t']==64, ['x', 'y']]
| x | y | |
|---|---|---|
| B | 20.0 | 1.0 |
# 't'列が64でない行(df['t']!=64と同じ)
df.loc[~(df['t']==64)]
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
# 't'列が64より大きくかつ'player'列が'hyuga'である行
df.loc[(df['t']>64) & (df['player'] == 'hyuga')]
| t | player | x | y | |
|---|---|---|---|---|
| D | 600 | hyuga | 32.5 | 2.5 |
# 'player'列が'misaki'または'hyuga'である行で,'x','y'列のみ抽出
df.loc[(df['player']=='misaki') | (df['player']=='hyuga'), ['x', 'y']]
| x | y | |
|---|---|---|
| B | 20.0 | 1.0 |
| D | 32.5 | 2.5 |
# 'x'列の値が'y'列の値より大きい行
df.loc[df['x'] > df['y']]
| t | player | x | y | |
|---|---|---|---|---|
| B | 64 | misaki | 20.0 | 1.0 |
| D | 600 | hyuga | 32.5 | 2.5 |
# 'x'列の値が'y'列の値より大きい行で'player'列のみ抽出
df.loc[df['x'] > df['y'], ['player']]
| player | |
|---|---|
| B | misaki |
| D | hyuga |
4.4.3. ブールインデックス参照による値の変更#
ブールインデックス参照で条件付き抽出したDataFrameに値を代入することで,条件を満たす要素だけ変更することができる.
# 't'==64の'player'を'wakashimazu'に変更
df2 = df.copy()
df2.loc[df['t']==350, 'player'] = 'wakashimazu'
df2
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakashimazu | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
# 't'>64の'x'と'y'を0に変更
df2 = df.copy()
df2.loc[df['t'] > 64, ['x', 'y']] = 0
df2
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 0.0 | 0.0 |
| D | 600 | hyuga | 0.0 | 0.0 |
4.4.4. 欠損値の処理#
# 欠損値を含むDataFrameの作成
df = pd.DataFrame(np.array([[np.nan, 1, 2], [3, np.nan, 5], [6, 7, 8], [np.nan, np.nan, np.nan]]),
columns=['a', 'b', 'c'])
df
| a | b | c | |
|---|---|---|---|
| 0 | NaN | 1.0 | 2.0 |
| 1 | 3.0 | NaN | 5.0 |
| 2 | 6.0 | 7.0 | 8.0 |
| 3 | NaN | NaN | NaN |
欠損値の検出
NaNの検出にはisnaメソッドまたはpd.isnull関数を用いる.どちらも動作は同じで,NaNの箇所がTrue,それ以外がFalseとなる.
df.isna()
| a | b | c | |
|---|---|---|---|
| 0 | True | False | False |
| 1 | False | True | False |
| 2 | False | False | False |
| 3 | True | True | True |
pd.isnull(df)
| a | b | c | |
|---|---|---|---|
| 0 | True | False | False |
| 1 | False | True | False |
| 2 | False | False | False |
| 3 | True | True | True |
欠損値の削除
欠損値の削除にはdropnaメソッドを用いる:
df.dropna(axis=0, how='any')
引数にaxis=0を指定した場合は行,axis=1の場合は列が削除される.
引数にhow='any'を指定した場合,行/列にNaNが1つでも含まれれば削除される.
一方,how='all'の場合,行/列の全ての要素がNaNの場合に削除される.
# 欠損値を1つでも含む行を削除
df.dropna(axis=0, how='any')
| a | b | c | |
|---|---|---|---|
| 2 | 6.0 | 7.0 | 8.0 |
# 欠損値を1つでも含む列を削除
df.dropna(axis=1, how='any')
| 0 |
|---|
| 1 |
| 2 |
| 3 |
# 全ての要素が欠損値である行を削除
df.dropna(axis=0, how='all')
| a | b | c | |
|---|---|---|---|
| 0 | NaN | 1.0 | 2.0 |
| 1 | 3.0 | NaN | 5.0 |
| 2 | 6.0 | 7.0 | 8.0 |
欠損値の置換
欠損値NaNを他の値で置換するにはfillnaメソッドを用いる:
df.fillna(value=置換後の値)
valueに数値を指定すると,全ての欠損値がその数値で置換される.
# 欠損値を0で置換
df.fillna(0)
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 1.0 | 2.0 |
| 1 | 3.0 | 0.0 | 5.0 |
| 2 | 6.0 | 7.0 | 8.0 |
| 3 | 0.0 | 0.0 | 0.0 |
4.4.5. 演習問題#
次のcsvファイルをダウンロードし,カレントディレクトリに保存せよ:player_all.csv
このファイルには,2017年度にヨーロッパリーグ(イングランド,フランス,ドイツ,イタリア,スペイン)に所属していた選手のデータが保存されている.
※ 本データはPappalardo-Wyscoutデータセットを加工したものである(詳細はPappalardo-Wyscoutデータセット).
ダウンロードしたcsvファイルをdfに読み込め.ただし,以下のオプションを指定せよ:
header=0:最初の行を列ラベルに設定index_col='player_id':選手IDを行ラベル(index)に設定na_values=0:値が0の要素を欠損値NaNで置き換える
# 解答欄
df =
以下はplayer_all.csvの保存先のurlである:
url = 'https://tnarizuka.github.io/sports_data_programming/chap_4/player_all.csv'
このcsvファイルをurlからdfに読み込め.ただし,同様のオプションを指定せよ.
# 解答欄
df =
身長(height)が2m以上の選手を抽出せよ
# 解答欄
国籍(nationality)が日本の選手を抽出せよ
# 解答欄
国籍(nationality)がケニアの選手を抽出せよ
# 解答欄
出生地(birth_area)がケニアの選手を抽出せよ
# 解答欄
利き足(foot)が右(right)の選手の身長と体重を抽出せよ
# 解答欄
スペインリーグに所属し,ポジション(role)がフォワードの選手を抽出せよ
※ まずdf['role'].unique()によって,role列に含まれる値を確認する
# まず,role列の値を確認する
df['role'].unique()
array(['MD', 'DF', 'GK', 'FW'], dtype=object)
# 解答欄
所属リーグ名(league)と出生地名(birth_area)が同じ選手を抽出し,先頭から10行だけ表示せよ
# 解答欄
league列内のEnglandをイングランドに変更せよ
# 解答欄
イタリアリーグのデータだけ抽出し,player_Italy.csvという名前でcsvファイルに保存せよ.
# 解答欄
自分の好きな条件でデータを抽出せよ
# 解答欄
4.5. DataFrameの演算と集計#
4.5.1. 演算規則#
まず,NumPyの演算規則は以下のようにまとめられた:
NumPy配列と数値の演算は,配列の全ての要素に演算が適用される
同じ形状を持つ2つの配列の演算は,各配列の同じ要素同士で演算が行われる.
異なる形状を持つ配列の演算には特別な規則(ブロードキャスト)が適用される.
Pandasの基本的な演算規則はNumPyと似ているが,DataFrame(Series)にはラベルが付与されているのでやや挙動が異なる.
四則演算については+,-,/,*などの演算子で実現できるが,df.addやdf.subなどの算術メソッドを用いると,より細かい制御が可能である.
df1 = pd.DataFrame(np.arange(12).reshape(4, 3), columns=['a', 'b', 'c'], dtype='float')
df1
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 1.0 | 2.0 |
| 1 | 3.0 | 4.0 | 5.0 |
| 2 | 6.0 | 7.0 | 8.0 |
| 3 | 9.0 | 10.0 | 11.0 |
df2 = pd.DataFrame(2*np.ones(15).reshape(5, 3), columns=['a', 'b', 'd'])
df2
| a | b | d | |
|---|---|---|---|
| 0 | 2.0 | 2.0 | 2.0 |
| 1 | 2.0 | 2.0 | 2.0 |
| 2 | 2.0 | 2.0 | 2.0 |
| 3 | 2.0 | 2.0 | 2.0 |
| 4 | 2.0 | 2.0 | 2.0 |
数値との演算
DataFrame(およびSeries)と数値の演算は全ての要素に演算が適用される.
# 1を足す
df1 + 1
| a | b | c | |
|---|---|---|---|
| 0 | 1.0 | 2.0 | 3.0 |
| 1 | 4.0 | 5.0 | 6.0 |
| 2 | 7.0 | 8.0 | 9.0 |
| 3 | 10.0 | 11.0 | 12.0 |
# 1を足す(addメソッドを用いる)
df1.add(1)
| a | b | c | |
|---|---|---|---|
| 0 | 1.0 | 2.0 | 3.0 |
| 1 | 4.0 | 5.0 | 6.0 |
| 2 | 7.0 | 8.0 | 9.0 |
| 3 | 10.0 | 11.0 | 12.0 |
# 2を掛ける
df1 * 2
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 2.0 | 4.0 |
| 1 | 6.0 | 8.0 | 10.0 |
| 2 | 12.0 | 14.0 | 16.0 |
| 3 | 18.0 | 20.0 | 22.0 |
# 2を掛ける(mulメソッドを用いる)
df1.mul(2)
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 2.0 | 4.0 |
| 1 | 6.0 | 8.0 | 10.0 |
| 2 | 12.0 | 14.0 | 16.0 |
| 3 | 18.0 | 20.0 | 22.0 |
列(Series)同士の演算
# 'a'列と'b'列の和
df1['a'] + df1['b']
0 1.0
1 7.0
2 13.0
3 19.0
dtype: float64
# 'a'列と'b'列の積
df1['a'] * df1['b']
0 0.0
1 12.0
2 42.0
3 90.0
dtype: float64
# 'a'列と'b'列の割り算
df1['a'] / df1['b']
0 0.000
1 0.750
2 0.857
3 0.900
dtype: float64
# 'c'列を2乗する
df1['c']**2
0 4.0
1 25.0
2 64.0
3 121.0
Name: c, dtype: float64
# 'a'列から5を引いて2乗する
(df1['a'] - 5)**2
0 25.0
1 4.0
2 1.0
3 16.0
Name: a, dtype: float64
DataFrame同士の演算
行ラベル(index)と列ラベル(columns)が同じ要素同士で演算が行われる.
異なるラベルが存在する場合は列と行が拡張され,欠損値NaNとなる.
# ラベルが同じDataFrame同士の足し算
df1+df1
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 2.0 | 4.0 |
| 1 | 6.0 | 8.0 | 10.0 |
| 2 | 12.0 | 14.0 | 16.0 |
| 3 | 18.0 | 20.0 | 22.0 |
# ラベルが異なるDataFrame間の足し算
# 共通する'a', 'b'列は足し算されるが,df1にしかない'c'列とdf2にしかない'd'列は欠損値となる
df1+df2
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 2.0 | 3.0 | NaN | NaN |
| 1 | 5.0 | 6.0 | NaN | NaN |
| 2 | 8.0 | 9.0 | NaN | NaN |
| 3 | 11.0 | 12.0 | NaN | NaN |
| 4 | NaN | NaN | NaN | NaN |
DataFrameとSeries(特定の列)の演算
df1
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 1.0 | 2.0 |
| 1 | 3.0 | 4.0 | 5.0 |
| 2 | 6.0 | 7.0 | 8.0 |
| 3 | 9.0 | 10.0 | 11.0 |
# df1の'c'列をs1として抽出
s1 = df1['c']
s1
0 2.0
1 5.0
2 8.0
3 11.0
Name: c, dtype: float64
DataFrameの各列とSeriesの演算を行いたい場合は算術メソッドを用いてaxis=0を指定する.
※ 各種算術メソッドでは,デフォルトでaxis=1となっているので注意.
# 各列にs1を加える
df1.add(s1, axis=0)
| a | b | c | |
|---|---|---|---|
| 0 | 2.0 | 3.0 | 4.0 |
| 1 | 8.0 | 9.0 | 10.0 |
| 2 | 14.0 | 15.0 | 16.0 |
| 3 | 20.0 | 21.0 | 22.0 |
# 各列からs1を引く
df1.sub(s1, axis=0)
| a | b | c | |
|---|---|---|---|
| 0 | -2.0 | -1.0 | 0.0 |
| 1 | -2.0 | -1.0 | 0.0 |
| 2 | -2.0 | -1.0 | 0.0 |
| 3 | -2.0 | -1.0 | 0.0 |
# 各列をs1で割る
df1.div(s1, axis=0)
| a | b | c | |
|---|---|---|---|
| 0 | 0.000 | 0.500 | 1.0 |
| 1 | 0.600 | 0.800 | 1.0 |
| 2 | 0.750 | 0.875 | 1.0 |
| 3 | 0.818 | 0.909 | 1.0 |
# 各列にs1を掛ける
df1.mul(s1, axis=0)
| a | b | c | |
|---|---|---|---|
| 0 | 0.0 | 2.0 | 4.0 |
| 1 | 15.0 | 20.0 | 25.0 |
| 2 | 48.0 | 56.0 | 64.0 |
| 3 | 99.0 | 110.0 | 121.0 |
4.5.2. データの集計#
PandasにもNumPyと同様にデータの集計を行う様々なメソッドが用意されている.
各メソッドで集計の方向を指定するにはaxis引数を用いる.
列ごとに集計したい場合はaxis=0,行ごとの場合はaxis=1を指定する.
メソッド |
説明 |
option |
|---|---|---|
min |
最小値 |
|
max |
最大値 |
|
sum |
合計 |
|
mean |
平均値 |
|
median |
中央値 |
|
mode |
最頻値 |
|
var |
分散 |
ddof(不偏:1,標本:0) |
std |
標準偏差 |
ddof(不偏:1,標本:0) |
count |
NA値ではない要素数 |
|
diff |
階差 |
periods(何行前との差を取るか) |
cumusum |
累積和 |
df = pd.DataFrame(np.random.randint(0, 100, [5, 4]),
columns=['a', 'b', 'c', 'd'])
df
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 66 | 41 | 46 | 62 |
| 1 | 14 | 42 | 92 | 64 |
| 2 | 34 | 20 | 2 | 98 |
| 3 | 82 | 91 | 31 | 81 |
| 4 | 32 | 71 | 68 | 49 |
# 各列の最大値
df.max(axis=0)
a 82
b 91
c 92
d 98
dtype: int64
# 各行の最大値
df.max(axis=1)
0 66
1 92
2 98
3 91
4 71
dtype: int64
# 各列の和
df.sum(axis=0)
a 228
b 265
c 239
d 354
dtype: int64
# 各行の和
df.sum(axis=1)
0 215
1 212
2 154
3 285
4 220
dtype: int64
# 各列の平均
df.mean(axis=0)
a 45.6
b 53.0
c 47.8
d 70.8
dtype: float64
# 各行の平均
df.mean(axis=1)
0 53.75
1 53.00
2 38.50
3 71.25
4 55.00
dtype: float64
# 各列の標本標準偏差
df.std(ddof=0, axis=0)
a 24.735
b 24.988
c 30.805
d 16.987
dtype: float64
# 2行前との差分
df.diff(periods=2, axis=0)
| a | b | c | d | |
|---|---|---|---|---|
| 0 | NaN | NaN | NaN | NaN |
| 1 | NaN | NaN | NaN | NaN |
| 2 | -32.0 | -21.0 | -44.0 | 36.0 |
| 3 | 68.0 | 49.0 | -61.0 | 17.0 |
| 4 | -2.0 | 51.0 | 66.0 | -49.0 |
条件付き抽出したデータの集計
まず,演習問題で扱った"player_all.csv"をdfに読み込む
df = pd.read_csv('./player_all.csv', header=0, index_col='player_id', na_values=0)
df
| name | team_id | role | height | weight | foot | nationality | birth_area | birthday | league | |
|---|---|---|---|---|---|---|---|---|---|---|
| player_id | ||||||||||
| 3319 | M_Özil | 1609 | MD | 180.0 | 76.0 | left | Germany | Germany | 1988/10/15 | England |
| 3560 | Nach_Monreal | 1609 | DF | 179.0 | 72.0 | left | Spain | Spain | 1986/02/26 | England |
| 7855 | L_Koscielny | 1609 | DF | 186.0 | 75.0 | right | Poland | France | 1985/09/10 | England |
| 7870 | A_Ramsey | 1609 | MD | 183.0 | 76.0 | right | Wales | Wales | 1990/12/26 | England |
| 7882 | P_Čech | 1609 | GK | 196.0 | 90.0 | left | Czec_Republic | Czec_Republic | 1982/05/20 | England |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 266885 | M_Olunga | 756 | FW | 188.0 | 80.0 | left | Kenya | Kenya | 1994/03/26 | Spain |
| 282448 | Alei_García | 756 | MD | 173.0 | 74.0 | right | Spain | Spain | 1997/06/28 | Spain |
| 366374 | K_Soni | 756 | MD | 182.0 | 77.0 | left | Cameroon | Cameroon | 1998/04/17 | Spain |
| 443324 | Dougla_Luiz | 756 | MD | 178.0 | 65.0 | right | Brazil | Brazil | 1998/05/09 | Spain |
| 508686 | M_Lizak | 756 | GK | 192.0 | 78.0 | NaN | Poland | Poland | 1996/07/15 | Spain |
2439 rows × 10 columns
# 国籍が'Japan'の選手の平均身長
df.loc[df['nationality']=='Japan', ['height']].mean()
height 176.786
dtype: float64
# 国籍が'England'の選手の平均身長
df.loc[df['nationality']=='England', ['height']].mean()
height 182.402
dtype: float64
# 右利きの選手の平均身長と平均体重
df.loc[df['foot']=='right', ['height', 'weight']].mean()
height 182.748
weight 76.712
dtype: float64
# 左利きの選手の平均身長と平均体重
df.loc[df['foot']=='left', ['height', 'weight']].mean()
height 181.560
weight 75.358
dtype: float64
# 身長が最大の選手
df.loc[df['height']==df['height'].max()]
| name | team_id | role | height | weight | foot | nationality | birth_area | birthday | league | |
|---|---|---|---|---|---|---|---|---|---|---|
| player_id | ||||||||||
| 283062 | V_Milinković-Savić | 3185 | GK | 202.0 | 92.0 | right | Serbia | Spain | 1997/02/20 | Italy |
# 体重が最大の選手
df.loc[df['weight']==df['weight'].max()]
| name | team_id | role | height | weight | foot | nationality | birth_area | birthday | league | |
|---|---|---|---|---|---|---|---|---|---|---|
| player_id | ||||||||||
| 8488 | W_Morgan | 1631 | DF | 186.0 | 101.0 | right | Jamaica | England | 1984/01/21 | England |
| 8726 | A_Begović | 1659 | GK | 199.0 | 101.0 | right | Canada | Bosnia-Herzegovina | 1987/06/20 | England |
4.6. DataFrameの整形#
df = pd.read_csv('./df_sample.csv', header=0, index_col=0)
df
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
4.6.1. 行・列の追加と削除#
行・列の追加:拡張代入
DataFrameに値を代入する際に存在しない行ラベルや列ラベルを指定すると,新たな行や列が追加される.
これを拡張代入と呼ぶ.
拡張代入はloc属性と角括弧による参照が対応している(iloc属性は対応していない).
※ この他に,列を追加するassinメソッド,行を追加するappendメソッドがあるがここでは触れない.
# loc属性による'z'列の追加
df2 = df.copy()
df2.loc[:, 'z'] = 5
df2
| t | player | x | y | z | |
|---|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 | 5 |
| B | 64 | misaki | 20.0 | 1.0 | 5 |
| C | 350 | wakabayashi | 10.5 | 50.5 | 5 |
| D | 600 | hyuga | 32.5 | 2.5 | 5 |
# 角括弧による'z'列の追加
df2 = df.copy()
df2['z'] = [1,2,3,4]
df2
| t | player | x | y | z | |
|---|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 | 1 |
| B | 64 | misaki | 20.0 | 1.0 | 2 |
| C | 350 | wakabayashi | 10.5 | 50.5 | 3 |
| D | 600 | hyuga | 32.5 | 2.5 | 4 |
# loc属性による'E'行の追加
df2 = df.copy()
df2.loc['E'] = [1000, 'ishizaki', 50.0, 20.0]
df2
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| B | 64 | misaki | 20.0 | 1.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
| E | 1000 | ishizaki | 50.0 | 20.0 |
行・列の削除:dropメソッド
列を削除する場合はdf.drop(columns=['列名1', '列名2'])とする.
行を削除する場合はdf.drop(index=['行名1', '行名2'])とする.
※ バージョン0.21.0より前の場合はaxis引数を指定する必要がある.
# 'B'行の削除
df.drop(index=['B'])
| t | player | x | y | |
|---|---|---|---|---|
| A | 2 | ozora | 5.0 | 10.0 |
| C | 350 | wakabayashi | 10.5 | 50.5 |
| D | 600 | hyuga | 32.5 | 2.5 |
# 't'列の削除
df.drop(columns=['t'])
| player | x | y | |
|---|---|---|---|
| A | ozora | 5.0 | 10.0 |
| B | misaki | 20.0 | 1.0 |
| C | wakabayashi | 10.5 | 50.5 |
| D | hyuga | 32.5 | 2.5 |
# 't'列と'player'列の削除
df.drop(columns=['t', 'player'])
| x | y | |
|---|---|---|
| A | 5.0 | 10.0 |
| B | 20.0 | 1.0 |
| C | 10.5 | 50.5 |
| D | 32.5 | 2.5 |
4.6.2. データの並び替え#
Pandasには特定の列の値によってデータを並び替えるsort_valuesメソッドと,行ラベル(index)によってデータを並び替えるsort_indexメソッドが用意されている.
dict_data = {'t':[2, 64, 350, 600],\
'player':['ozora', 'misaki', 'wakabayashi', 'hyuga'],\
'x':[5.0, 20.0, 10.5, 32.5],
'y':[10.0, 1.0, 50.5, 2.5]}
df = pd.DataFrame(dict_data, index=[2, 0, 1, 3])
df
| t | player | x | y | |
|---|---|---|---|---|
| 2 | 2 | ozora | 5.0 | 10.0 |
| 0 | 64 | misaki | 20.0 | 1.0 |
| 1 | 350 | wakabayashi | 10.5 | 50.5 |
| 3 | 600 | hyuga | 32.5 | 2.5 |
値によるソート:sort_valuesメソッド
特定の行・列の値によってソートしたい場合はsort_valuesメソッドを用いる:
df.sort_values(['ラベル1', 'ラベル2', ...], axis=0, ascending=True)
第1引数にはソートに用いるラベル名を指定する.
ラベル名を複数指定すると,まず1つ目のラベルでソートし,その後順に2つ目以降のラベルでソートされる.
また,ソートの方向はaxis引数で指定し,特定の列でソートする場合にはaxis=0,特定の行でソートする場合にはaxis=1を指定する.
dict_data = {'half': [1, 2, 1, 2],
't':[2, 64, 350, 600],
'player':['ozora', 'misaki', 'wakabayashi', 'hyuga'],
'x':[5.0, 20.0, 10.5, 32.5],
'y':[10.0, 1.0, 50.5, 2.5]}
df = pd.DataFrame(dict_data, index=[2, 0, 1, 3])
df
| half | t | player | x | y | |
|---|---|---|---|---|---|
| 2 | 1 | 2 | ozora | 5.0 | 10.0 |
| 0 | 2 | 64 | misaki | 20.0 | 1.0 |
| 1 | 1 | 350 | wakabayashi | 10.5 | 50.5 |
| 3 | 2 | 600 | hyuga | 32.5 | 2.5 |
# 'half'列,'t'列の順にソート
df.sort_values(['half', 't'], axis=0, ascending=True)
| half | t | player | x | y | |
|---|---|---|---|---|---|
| 2 | 1 | 2 | ozora | 5.0 | 10.0 |
| 1 | 1 | 350 | wakabayashi | 10.5 | 50.5 |
| 0 | 2 | 64 | misaki | 20.0 | 1.0 |
| 3 | 2 | 600 | hyuga | 32.5 | 2.5 |
行・列ラベルによるソート:sort_indexメソッド
上のdfは行ラベルが[2,0,1,3]という順になっている.このような場合にsort_indexメソッドを用いると,行ラベル/列ラベルによってDataFrameを辞書順に並び替えることができる:
df.sort_index(axis=0, ascending=True)
行ラベルか列ラベルかはaxis引数で指定する.並び替えの方法(昇順か降順)はascending引数に指定し,Trueの場合は昇順,Falseの場合は降順となる.
# 行ラベルの昇順でソート
df.sort_index(axis=0, ascending=True)
| half | t | player | x | y | |
|---|---|---|---|---|---|
| 0 | 2 | 64 | misaki | 20.0 | 1.0 |
| 1 | 1 | 350 | wakabayashi | 10.5 | 50.5 |
| 2 | 1 | 2 | ozora | 5.0 | 10.0 |
| 3 | 2 | 600 | hyuga | 32.5 | 2.5 |
# 行ラベルの降順でソート
df.sort_index(axis=0, ascending=False)
| half | t | player | x | y | |
|---|---|---|---|---|---|
| 3 | 2 | 600 | hyuga | 32.5 | 2.5 |
| 2 | 1 | 2 | ozora | 5.0 | 10.0 |
| 1 | 1 | 350 | wakabayashi | 10.5 | 50.5 |
| 0 | 2 | 64 | misaki | 20.0 | 1.0 |
# 列ラベルの昇順でソート
df.sort_index(axis=1, ascending=True)
| half | player | t | x | y | |
|---|---|---|---|---|---|
| 2 | 1 | ozora | 2 | 5.0 | 10.0 |
| 0 | 2 | misaki | 64 | 20.0 | 1.0 |
| 1 | 1 | wakabayashi | 350 | 10.5 | 50.5 |
| 3 | 2 | hyuga | 600 | 32.5 | 2.5 |
4.6.3. 行ラベル・列ラベルの変更#
df = pd.DataFrame(np.arange(12).reshape(4, 3),
index=[3, 0, 2, 1],
columns=['b', 'c', 'a'])
df
| b | c | a | |
|---|---|---|---|
| 3 | 0 | 1 | 2 |
| 0 | 3 | 4 | 5 |
| 2 | 6 | 7 | 8 |
| 1 | 9 | 10 | 11 |
index属性・columns属性への代入
# 行ラベルを変更する
df2 = df.copy()
df2.index = ['A', 'B', 'C', 'D']
df2
| b | c | a | |
|---|---|---|---|
| A | 0 | 1 | 2 |
| B | 3 | 4 | 5 |
| C | 6 | 7 | 8 |
| D | 9 | 10 | 11 |
# 列ラベルを変更する
df2 = df.copy()
df2.columns = [0, 1, 2]
df2
| 0 | 1 | 2 | |
|---|---|---|---|
| 3 | 0 | 1 | 2 |
| 0 | 3 | 4 | 5 |
| 2 | 6 | 7 | 8 |
| 1 | 9 | 10 | 11 |
行ラベル(index)を連番で振り直す:reset_indexメソッド
reset_indexメソッドを用いると,行ラベル(index)を0から始まる連番で振り直すことができる.
デフォルトではdrop引数が0になっており,元のindexが新たな列としてDataFrameに残る.
元のindexを削除したい場合はdrop=1を指定する.
# 元のindexを残す
df.reset_index(drop=0)
| index | b | c | a | |
|---|---|---|---|---|
| 0 | 3 | 0 | 1 | 2 |
| 1 | 0 | 3 | 4 | 5 |
| 2 | 2 | 6 | 7 | 8 |
| 3 | 1 | 9 | 10 | 11 |
# 元のindexを削除
df.reset_index(drop=1)
| b | c | a | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
| 2 | 6 | 7 | 8 |
| 3 | 9 | 10 | 11 |
4.7. 章末問題#
問題A
次のcsvファイルをダウンロードし,カレントディレクトリに保存せよ:player_all.csv
このファイルには,2017年度にヨーロッパリーグ(イングランド,フランス,ドイツ,イタリア,スペイン)に所属していた選手のデータが保存されている.
player_all.csvファイルをdfに読み込め
# 解答欄
dfの先頭から2行を表示せよ
# 解答欄
肥満度を表す指標としてBMIが知られている.BMIは身長と体重を用いて以下で定義される:
\[ \mathrm{BMI} = \frac{体重 [kg]}{(身長 [m])^2} \]身長(
height)の単位をcmからmに変換せよ.身長(
height)と体重(weight)からBMIを求め,BMI列を作成せよ.BMIが18.5未満の選手を抽出せよ.
※ この選手はRekeem Jordan Harper選手である.
※ 日本肥満学会の基準では,BMIが18.5未満の場合を痩せ型と定義している.dfをBMI列で昇順に並び替え,先頭から10行を表示せよ.
# 'height'の単位をcm->m
# BMIを求めて'BMI'列を作成
# BMIが18.5未満の選手を抽出
# BMI列で並び替えて先頭から10行を表示
ポジション(
role)ごとに,身長,体重,BMIの平均値を計算せよ.
# ディフェンダー('DF')
# ミッドフィルダー('MD')
# フォワード('FW')
# キーパー('GK')
問題B
次のcsvファイルをダウンロードし,カレントディレクトリに保存せよ:game.csv
このファイルには,ヨーロッパリーグ(イングランド,フランス,ドイツ,イタリア,スペイン)の2017年シーズンの全試合の結果が記録されている.
game.csvファイルをdfに読み込め
# 解答欄
1つのリーグを選び,このリーグの節数を求めよ.(節番号は
section列に記録されている.)
# 解答欄
新たに
total_score列を作成し,away_score列とhome_score列の合計を計算せよ.
# 解答欄
Homeチームの平均得点とAwayチームの平均得点をそれぞれ求めよ.
# 解答欄(Homeチーム)
# 解答欄(Awayチーム)
好きなチームを選び,そのチームのホームゲームとアウェイゲームの平均得点を求めよ.
# 解答欄(ホームゲーム)
# 解答欄(アウェイゲーム)
チーム別にシーズン総得点を求めよ.
# 解答欄