# (必須)モジュールのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
# 表示設定
np.set_printoptions(suppress=True, precision=3)
pd.set_option('display.precision', 3) # 小数点以下の表示桁
pd.set_option('display.max_rows', 50) # 表示する行数の上限
pd.set_option('display.max_columns', 15) # 表示する列数の上限
%precision 3
'%.3f'
7. トラッキングデータの解析#
7.1. トラッキングデータ#
7.1.1. Pettersen-Alfheimデータセット#
Pettersen-Alfheimデータセットはサッカーのトラッキングデータをまとめたデータセットである. 試合数は3試合と少ないが,2024年時点で一般公開されている数少ないサッカートラッキングデータである.
7.1.2. データセットの内容#
本データセットに含まれるトラッキングデータはノルウェーのAlfheimスタジアムにおいて取得されている. 対象となる試合はAlfheimスタジアムを本拠地とするTromsø ILの3試合である. データセットには試合映像とGPSデバイスによって取得された位置座標のデータ(トラッキングデータ)が含まれている. ただし,トラッキングデータの取得対象はTromsø ILの選手のみである. また,選手のプライバシー保護のためトラッキングデータから選手の個人情報は除去されており,データ解析によって選手を特定することは禁止されている.
トラッキングデータの位置座標は以下のような座標系において,1秒間に20フレーム(20fps)の解像度で取得されている.
原点:フィールドの左下
\(x\)軸:長軸方向(\(0 \le x \le 105\))
\(y\)軸:短軸方向(\(0 \le x \le 68\))
単位はm
7.2. データの前処理#
ここでは,Tromsø IL vs Strømsgodsetのトラッキングデータを解析対象とする. まずはトラッキングデータのcsvファイルを以下からダウンロードし,カレントディレクトリに移動しておく:
なお,以下では前半の解析例だけを示す.
7.2.1. データの加工・整形#
データの読み込み
ダウンロードしたcsvファイルをdfという名前でDataFrameに読み込む.
その際に列ラベル(columns)を指定しておく.
df = pd.read_csv('./2013-11-03_tromso_stromsgodset_first.csv',
header=None, encoding='utf-8',
names=['time','id','x','y','heading','direction','energy','speed','total_distance'])
df.head(2)
| time | id | x | y | heading | direction | energy | speed | total_distance | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013-11-03 18:01:09 | 2 | 26.573 | 29.436 | 0.800 | 0.824 | 150.662 | 0.968 | 255.584 |
| 1 | 2013-11-03 18:01:09 | 5 | 35.550 | 30.268 | 1.158 | -0.175 | 364.309 | 0.624 | 297.861 |
時刻・選手ID・位置座標の抽出
読み込んだデータには向き(heading, direction)や速さ(speed)などの列が含まれているが,以下では時刻(time),選手ID(id),位置座標(x, y)の情報だけを用いるので,これらを抽出する.
df = df[['time', 'id', 'x', 'y']]
df.head(2)
| time | id | x | y | |
|---|---|---|---|---|
| 0 | 2013-11-03 18:01:09 | 2 | 26.573 | 29.436 |
| 1 | 2013-11-03 18:01:09 | 5 | 35.550 | 30.268 |
DataFrameの並び替え
次に,sort_valuesメソッドを用いて,time列,id列をキーにしてdfをソートする.これによりdfの行方向の並びが時間順となる(同一時刻の行は選手ID順となる).
# time列, id列でソートしてindexを振り直す
df = df.sort_values(['time', 'id']).reset_index(drop=1)
df.head(2)
| time | id | x | y | |
|---|---|---|---|---|
| 0 | 2013-11-03 18:01:09 | 1 | 53.138 | 44.062 |
| 1 | 2013-11-03 18:01:09 | 2 | 26.573 | 29.436 |
日時の変換
time列には試合が行われた年月日および時刻が文字列として保存されている.
このうち,年月日の情報は不要なので,str.splitメソッドを用いて年月日と時刻を別々の列に分割する.
temp = df['time'].str.split(' ', expand=True)
temp.head(2)
| 0 | 1 | |
|---|---|---|
| 0 | 2013-11-03 | 18:01:09 |
| 1 | 2013-11-03 | 18:01:09 |
時刻の情報は18:01:09という形式の文字列である.
これを以下の手順に従い試合開始からの経過時間に変換する:
時・分・秒を
str.splitメソッドによって別々の列に分割する第0行からの経過時間(秒)に変換し,
dfの'time'列に追加する
# 経過時間(秒)に変換
times = temp[1].str.split(':', expand=True).astype(float)
sec = times[1]*60 + times[2]
df['time'] = sec - sec.iloc[0]
df.head(2)
| time | id | x | y | |
|---|---|---|---|---|
| 0 | 0.0 | 1 | 53.138 | 44.062 |
| 1 | 0.0 | 2 | 26.573 | 29.436 |
x座標,y座標のデータフレーム作成
全選手の \( x \) 座標と \( y \) 座標を格納した以下のようなデータフレーム(df_x,df_y)を作成する:
行ラベル(
index):フレーム番号1行=1フレーム=0.05秒
列ラベル(
columns):選手ID
player_id = df['id'].unique() # 選手ID
time = np.arange(0, df['time'].max()+0.05, 0.05) # 0.05秒刻みの経過時間
df_x = pd.DataFrame({'t': time}) # x座標のデータフレーム
df_y = pd.DataFrame({'t': time}) # y座標のデータフレーム
# データフレームに各選手の座標を格納
for u in player_id:
df_u = df.loc[df['id']==u] # 選手uだけ抽出
df_u.index = (df_u['time']/0.05).round().astype(int) # indexをフレーム番号に設定
df_x[u], df_y[u] = np.nan, np.nan
df_x.loc[df_u.index, u] = df_u['x']
df_y.loc[df_u.index, u] = df_u['y']
df_x, df_y = df_x[player_id], df_y[player_id] # 't'列を除去
df_x.head()
| 1 | 2 | 5 | 7 | 8 | 9 | 10 | 12 | 13 | 14 | 15 | 6 | 11 | 3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 53.138 | 26.573 | 35.550 | 41.586 | 28.507 | 32.254 | 45.247 | 74.59 | 21.029 | 28.530 | 50.084 | NaN | NaN | NaN |
| 1 | 53.138 | 26.609 | 35.545 | 41.572 | 28.537 | 32.254 | 45.247 | 74.59 | 21.070 | 28.528 | 50.105 | NaN | NaN | NaN |
| 2 | 53.138 | 26.645 | 35.539 | 41.557 | 28.568 | 32.254 | 45.247 | 74.59 | 21.114 | 28.525 | 50.134 | NaN | NaN | NaN |
| 3 | 53.138 | 26.682 | 35.534 | 41.543 | 28.596 | 32.254 | 45.247 | 74.59 | 21.161 | 28.521 | 50.169 | NaN | NaN | NaN |
| 4 | 53.138 | 26.719 | 35.528 | 41.529 | 28.624 | 32.254 | 45.247 | 74.59 | 21.209 | 28.516 | 50.210 | NaN | NaN | NaN |
df_y.head()
| 1 | 2 | 5 | 7 | 8 | 9 | 10 | 12 | 13 | 14 | 15 | 6 | 11 | 3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 44.062 | 29.436 | 30.268 | 38.675 | 39.612 | 12.724 | 14.462 | 71.048 | 17.624 | 17.597 | 25.779 | NaN | NaN | NaN |
| 1 | 44.062 | 29.467 | 30.299 | 38.663 | 39.568 | 12.724 | 14.462 | 71.048 | 17.623 | 17.561 | 25.722 | NaN | NaN | NaN |
| 2 | 44.062 | 29.495 | 30.331 | 38.651 | 39.525 | 12.724 | 14.462 | 71.048 | 17.616 | 17.532 | 25.665 | NaN | NaN | NaN |
| 3 | 44.062 | 29.520 | 30.364 | 38.640 | 39.486 | 12.724 | 14.462 | 71.048 | 17.603 | 17.510 | 25.607 | NaN | NaN | NaN |
| 4 | 44.062 | 29.541 | 30.397 | 38.629 | 39.449 | 12.724 | 14.462 | 71.048 | 17.584 | 17.495 | 25.549 | NaN | NaN | NaN |
7.2.2. 不要な選手の除去#
df_x,df_yには以下の選手の座標が含まれている:
df_x.columns
Index([1, 2, 5, 7, 8, 9, 10, 12, 13, 14, 15, 6, 11, 3], dtype='object')
この中には,実際に試合に出場した選手の他に審判などの位置座標も含まれている. これら不要なデータを特定するため,選手IDごとに位置座標をプロットしてみる.
u = 6
fig, ax = plt.subplots(figsize=(2, 2))
ax.plot(df_x[u], df_y[u], '.', ms=0.1)
ax.set_xlim(0, 120); ax.set_ylim(0, 80)
ax.set_aspect('equal')
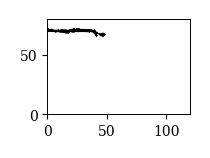
位置座標をプロットした結果を踏まえると,以下の10人が試合に出場した選手と考えられる:
1, 2, 5, 7, 8, 9, 10, 13, 14, 15
df_x,df_yからこれらの選手のデータだけ抽出する.
df_x2 = df_x[[1, 2, 5, 7, 8, 9, 10, 13, 14, 15]]
df_y2 = df_y[[1, 2, 5, 7, 8, 9, 10, 13, 14, 15]]
df_x2.head(2)
| 1 | 2 | 5 | 7 | 8 | 9 | 10 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 53.138 | 26.573 | 35.550 | 41.586 | 28.507 | 32.254 | 45.247 | 21.029 | 28.530 | 50.084 |
| 1 | 53.138 | 26.609 | 35.545 | 41.572 | 28.537 | 32.254 | 45.247 | 21.070 | 28.528 | 50.105 |
df_y2.head(2)
| 1 | 2 | 5 | 7 | 8 | 9 | 10 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 44.062 | 29.436 | 30.268 | 38.675 | 39.612 | 12.724 | 14.462 | 17.624 | 17.597 | 25.779 |
| 1 | 44.062 | 29.467 | 30.299 | 38.663 | 39.568 | 12.724 | 14.462 | 17.623 | 17.561 | 25.722 |
7.2.3. データの保存#
df_x2.to_csv('./x_1st.csv', header=True, index=True, encoding='utf-8')
df_y2.to_csv('./y_1st.csv', header=True, index=True, encoding='utf-8')
7.2.4. 演習問題#
前半と同様に後半のトラッキングデータを読み込み,前半と同様の手順でデータを加工・整形し,x_2nd.csv,y_2nd.csvという名前で保存せよ.
# 解答欄
Pettersen-Alfheimデータセットの前処理を行う関数を作成せよ.
# 解答欄
7.3. トラッキングデータ解析の基本#
7.3.1. データの読み込み#
改めて,作成したデータをdf_x,df_yというDataFrameに読み込む.
df_x = pd.read_csv('./x_1st.csv', encoding='utf-8', index_col=0)
df_y = pd.read_csv('./y_1st.csv', encoding='utf-8', index_col=0)
7.3.2. データの扱い方#
データの構造
データフレームdf_x,df_yは以下のような構造になっている:
行ラベル(
index):フレーム番号1行=1フレーム=0.05秒
列ラベル(
columns):選手ID
df_x.head(2)
| 1 | 2 | 5 | 7 | 8 | 9 | 10 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 53.138 | 26.573 | 35.550 | 41.586 | 28.507 | 32.254 | 45.247 | 21.029 | 28.530 | 50.084 |
| 1 | 53.138 | 26.609 | 35.545 | 41.572 | 28.537 | 32.254 | 45.247 | 21.070 | 28.528 | 50.105 |
df_y.head(2)
| 1 | 2 | 5 | 7 | 8 | 9 | 10 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 44.062 | 29.436 | 30.268 | 38.675 | 39.612 | 12.724 | 14.462 | 17.624 | 17.597 | 25.779 |
| 1 | 44.062 | 29.467 | 30.299 | 38.663 | 39.568 | 12.724 | 14.462 | 17.623 | 17.561 | 25.722 |
特定の時間帯の抽出
df_x,df_yの行ラベル(index)はフレーム番号に等しい.
1フレーム=0.05秒なので,試合開始 \(t\) 秒後の座標は\(20\times t\) 行目を参照すれば良い.
特定の時刻のデータを抽出するには,df_x,df_yからloc属性を用いて条件付き抽出を行う.
例えば,10秒〜20秒の時間帯だけ抽出するには,行ラベル(index)が200から400までの行を条件付き抽出すればよい.
df_x.loc[200:400]
| 1 | 2 | 5 | 7 | 8 | 9 | 10 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 200 | 54.117 | 24.796 | 37.753 | 41.883 | 27.185 | 32.940 | 43.509 | 21.114 | 27.968 | 53.166 |
| 201 | 54.274 | 24.816 | 37.778 | 41.877 | 27.184 | 32.941 | 43.544 | 21.073 | 27.968 | 53.314 |
| 202 | 54.434 | 24.837 | 37.806 | 41.872 | 27.185 | 32.942 | 43.581 | 21.042 | 27.942 | 53.467 |
| 203 | 54.598 | 24.858 | 37.835 | NaN | 27.187 | 32.942 | 43.621 | 21.021 | 27.790 | 53.626 |
| 204 | 54.765 | 24.879 | 37.866 | 41.866 | 27.190 | 32.941 | 43.661 | 21.009 | 27.794 | 53.791 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 396 | 52.730 | 13.496 | 27.312 | 26.922 | 12.059 | 19.891 | 33.062 | 14.049 | 22.357 | 55.207 |
| 397 | 52.852 | 13.704 | 27.404 | 27.127 | 12.069 | 20.135 | 33.228 | 14.204 | 22.507 | 55.274 |
| 398 | 52.978 | 13.916 | 27.493 | 27.336 | 12.084 | 20.381 | 33.396 | 14.359 | 22.656 | 55.339 |
| 399 | 53.105 | 14.133 | 27.580 | 27.549 | 12.103 | 20.629 | 33.565 | 14.513 | 22.804 | 55.402 |
| 400 | 53.236 | 14.355 | 27.666 | NaN | 12.127 | 20.877 | 33.736 | 14.666 | 22.952 | 55.463 |
201 rows × 10 columns
フレーム番号を秒単位に直すのが面倒な場合は,以下のようにindexを秒単位に変換したtimeというSeriesを作っておき,これを用いて条件付き抽出すればよい.
time = df_x.index * 0.05
df_x.loc[(time >= 10) & (time <= 20)]
| 1 | 2 | 5 | 7 | 8 | 9 | 10 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 200 | 54.117 | 24.796 | 37.753 | 41.883 | 27.185 | 32.940 | 43.509 | 21.114 | 27.968 | 53.166 |
| 201 | 54.274 | 24.816 | 37.778 | 41.877 | 27.184 | 32.941 | 43.544 | 21.073 | 27.968 | 53.314 |
| 202 | 54.434 | 24.837 | 37.806 | 41.872 | 27.185 | 32.942 | 43.581 | 21.042 | 27.942 | 53.467 |
| 203 | 54.598 | 24.858 | 37.835 | NaN | 27.187 | 32.942 | 43.621 | 21.021 | 27.790 | 53.626 |
| 204 | 54.765 | 24.879 | 37.866 | 41.866 | 27.190 | 32.941 | 43.661 | 21.009 | 27.794 | 53.791 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 396 | 52.730 | 13.496 | 27.312 | 26.922 | 12.059 | 19.891 | 33.062 | 14.049 | 22.357 | 55.207 |
| 397 | 52.852 | 13.704 | 27.404 | 27.127 | 12.069 | 20.135 | 33.228 | 14.204 | 22.507 | 55.274 |
| 398 | 52.978 | 13.916 | 27.493 | 27.336 | 12.084 | 20.381 | 33.396 | 14.359 | 22.656 | 55.339 |
| 399 | 53.105 | 14.133 | 27.580 | 27.549 | 12.103 | 20.629 | 33.565 | 14.513 | 22.804 | 55.402 |
| 400 | 53.236 | 14.355 | 27.666 | NaN | 12.127 | 20.877 | 33.736 | 14.666 | 22.952 | 55.463 |
201 rows × 10 columns
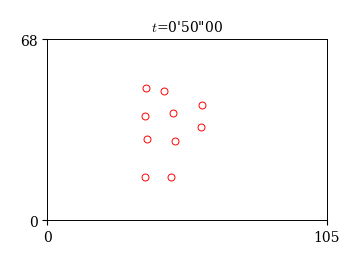
スナップショットの描画
以上を踏まえて,試合中の特定の時刻のスナップショットを描いてみよう.
fig, ax = plt.subplots()
# 抽出するフレーム番号
i=1000
# 位置の描画
x, y = df_x.loc[i], df_y.loc[i]
ax.plot(x, y, 'ro', ms=5, mfc='None')
# 時刻の表示
t = i*0.05 # フレーム番号を経過時間(秒)に変換
m, s = np.floor(t/60.).astype(int), np.floor(t % 60).astype(int)
ss = ("%.2f" % (t % 60 - s)).replace('.', '')[1:].zfill(2)
ax.set_title('$t$=%s\'%s\"%s' % (m, s, ss), fontsize=10)
ax.set_xlim(0, 105); ax.set_ylim(0, 68)
ax.set_xticks([0, 105])
ax.set_yticks([0, 68])
ax.set_aspect('equal')
7.3.3. 重心と標準偏差の計算#
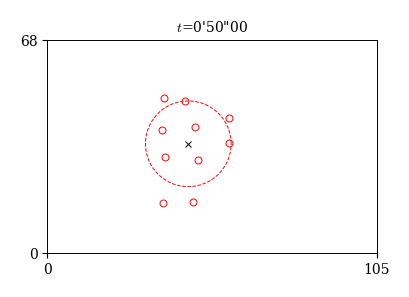
集団の動きを解析する際に,チーム全体のおおまかな位置と広がりを把握することは非常に重要である. これらの量の定義の仕方は色々と考えられるが,以下ではチームの平均位置(重心)と広がり(重心からの標準偏差)を計算する.
チームの重心
チームの重心は,キーパーを除く10人の平均位置を表す量で,以下のように定義される:
ここで,\( X_{u}(i),\ Y_{u}(i) \)は第 \( i \) フレームの選手 \( u \) の \( x,\ y \) 座標である.
トラッキングデータから重心を求めるには,フレームごとに10人の選手の \( x,\ y \) 座標の平均値を求めれば良い.
df_x_mean = df_x.mean(axis=1)
df_y_mean = df_y.mean(axis=1)
df_x_mean.head()
0 36.250
1 36.260
2 36.272
3 36.285
4 36.297
dtype: float64
チームの広がり
次に,チームの重心からの広がりを表す量を導入する. 定義は色々と考えられるが,ここでは以下の量を用いる.
これは,\( x \) 方向の分散と \( y \) 方向の分散の和の平方根である.
df_std = np.sqrt(df_x.var(ddof=0, axis=1) + df_y.var(ddof=0, axis=1))
df_std.head()
0 14.796
1 14.789
2 14.782
3 14.776
4 14.771
dtype: float64
重心と広がりの描画
fig, ax = plt.subplots(figsize=(4, 4))
# フレーム番号
i=1000
# 位置の描画
x, y = df_x.loc[i], df_y.loc[i]
ax.plot(x, y, 'ro', ms=5, mfc='None')
# 重心と標準偏差の描画
xc, yc = df_x_mean.loc[i], df_y_mean.loc[i]
std = df_std.loc[i]
ax.plot(xc, yc, 'kx')
theta = np.linspace(0, 2*np.pi)
ax.plot(xc + std*np.cos(theta), yc + std*np.sin(theta), 'r--')
# 時刻の表示
t = i*0.05
m, s = np.floor(t/60.).astype(int), np.floor(t % 60).astype(int)
ss = ("%.2f" % (t % 60 - s)).replace('.', '')[1:].zfill(2)
ax.set_title('$t$=%s\'%s\"%s' % (m, s, ss), fontsize=10)
ax.set_xlim(0, 105); ax.set_ylim(0, 68)
ax.set_xticks([0, 105])
ax.set_yticks([0, 68])
ax.set_aspect('equal')
7.3.4. 速度と速さの計算#
次に,位置座標から速度を求めてみよう. 2次元平面の速度はベクトルとして \( \vec{V} = (V_{x}, V_{y}) \) と表され,その大きさ \( |\vec{V}| \) を速さという.
フレーム \( i \) における速度の \( x, y \) 成分を \( V_{x}(i),\ V_{y}(i) \) ,速さを \( V(i) \) とすると,これらは以下のように計算される:
ここで,\( X(i),\ Y(i) \) は 第 \(i\) フレームの \(x, y\) 座標を表し,\(n\) はフレームの増分である. また,1フレームが0.05秒なので, \( 0.05n \) は \( n \) フレームの経過時間である. これより, \( V_{x}(i),\ V_{y}(i) \) の単位は m/s となる.
以下では,\( n=20 \)とし,20フレーム(=1秒間)の平均速度と速さを求める.
実装にはdiffメソッドを用いてnフレーム前との差分を計算すれば良い.
# 速度の計算
n = 20
df_vx = df_x.diff(n)/(0.05*n) # x方向の速度
df_vy = df_y.diff(n)/(0.05*n) # y方向の速度
# 速さの計算
df_v = np.sqrt(df_vx**2 + df_vy**2)
df_vx.tail()
| 1 | 2 | 5 | 7 | 8 | 9 | 10 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 56656 | NaN | -0.370 | 0.564 | 0.531 | 1.639 | -1.013 | -0.978 | 0.130 | 0.270 | 0.263 |
| 56657 | NaN | -0.431 | 0.571 | 0.529 | 1.623 | -0.973 | -0.900 | 0.174 | 0.265 | 0.248 |
| 56658 | NaN | -0.472 | 0.572 | 0.524 | 1.597 | -0.929 | -0.817 | 0.222 | 0.259 | 0.229 |
| 56659 | NaN | -0.494 | 0.566 | 0.517 | 1.564 | -0.881 | -0.731 | 0.273 | 0.252 | 0.206 |
| 56660 | NaN | -0.496 | 0.555 | 0.509 | 1.523 | -0.831 | -0.643 | 0.326 | 0.244 | 0.179 |
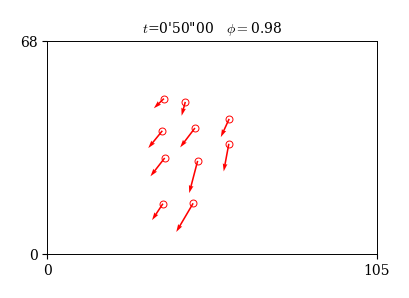
秩序変数
やや高度ではあるが,以下で定義される秩序変数(Order Parameter)という量を計算してみよう:
秩序変数は,集団内の移動方向の揃い具合を表す量で,統計物理学の分野でよく用いられる. その定義域は \( 0\le\phi(t)\le 1 \) であり,向きが揃っているほど1に近く,バラバラなほど0に近い値となる. 定義より,秩序変数は速度ベクトルから以下のように計算することができる.
df_v = np.sqrt(df_vx**2 + df_vy**2)
df_op = np.sqrt(np.sum(df_vx/df_v, axis=1)**2 + np.sum(df_vy/df_v, axis=1)**2) / 10
df_op.iloc[2500]
0.942
速度ベクトルの描画
速度が計算できたので,これらを描画してみよう.
速度ベクトルの描画には,matplotlibのquiver関数を用いて選手の位置を始点とする矢印を描けば良い.
また,秩序変数は時刻の横に文字列として出力する.
フレーム番号を変えると,矢印の向きの揃い具合と連動して秩序変数の値が変化することが分かる.
fig, ax = plt.subplots(figsize=(4,4))
# フレーム番号
i=1000
# 位置の描画
x, y = df_x.loc[i], df_y.loc[i]
ax.plot(x, y, 'ro', ms=5, mfc='None')
# 速度ベクトルの描画
vx, vy = df_vx.loc[i], df_vy.loc[i]
ax.quiver(x, y, vx, vy, color='r', angles='uv', units='xy', scale=0.7, width=0.5)
# 時刻と秩序変数の表示
op = np.round(df_op.loc[i], 2)
t = i*0.05
m, s = np.floor(t/60.).astype(int), np.floor(t % 60).astype(int)
ss = ("%.2f" % (t % 60 - s)).replace('.', '')[1:].zfill(2)
ax.set_title(f"$t$={m}'{s}\"{ss} $\\phi=${op}", fontsize=10)
ax.set_xlim(0, 105); ax.set_ylim(0, 68)
ax.set_xticks([0, 105])
ax.set_yticks([0, 68])
ax.set_aspect('equal')
7.3.5. 演習問題#
重心の \( x \) 座標と標準偏差の関係を可視化し,結果を考察せよ.
# 解答欄
選手ごとに速さのヒストグラムを求めよ.
# 解答欄
各選手の走行距離を計算せよ.
ヒント:細かい時間間隔での移動距離を全て足し合わせれば良い.
# 解答欄
各選手のスプリント回数を計算せよ
ヒント:Jリーグでは,時速25km以上で1秒以上走った回数をスプリント回数と定義している.
# 解答欄
7.3.6. フォーメーション#
サッカーのデータ解析において,フォーメーションを定量化・可視化することは重要な課題であり,今もホットなテーマの一つである. フォーメーションを定量化・可視化するには例えば,次のような方法が考えられる:
ある時間幅で選手ごとに平均位置を計算し可視化する
3-4-3, 4-4-2などの数字の組を用いて定量化する
各時刻で選手の隣接関係を定義し,ネットワークを用いて可視化する
ドロネー三角形分割(ドロネーネットワーク)の隣接行列を用いて定量化する
以下では,トラッキングデータを用いて,1の方法を簡単に解説する. 2については付録にまとめる.
絶対座標系での可視化
まずは試合前半の全選手の位置をフィールド上に色分けしてプロットしてみよう. この場合,座標原点がフィールドの左下に常に固定されているので,絶対座標系と呼ばれる.
fig, ax = plt.subplots(figsize=(3.5, 3))
for u in df_x.columns:
ax.plot(df_x[u], df_y[u], '.', ms=0.05)
ax.set_xlim(0, 105); ax.set_ylim(0, 68)
ax.set_xticks([0, 105])
ax.set_yticks([0, 68])
ax.set_aspect('equal')

プロットの結果を見て明らかなように,各選手はフィールド上を縦横無尽に動き周っていることがわかる. ポジションごとにおおよそ右サイドや中盤などの区分けはできるかもしれないが,この結果からチームのフォーメーションを推定することはできない.
重心座標系での可視化
次に,チームの重心(平均位置)を原点とする座標系に変換してみよう. これを重心座標系と呼ぶ. 直感的には,チームの平均位置(重心)から各選手の動きを観察することに対応する.
各選手の座標を重心座標系に変換するには,以下のように各時刻において選手の座標から重心の座標を引き算すればよい.
df_x_com = df_x.sub(df_x.mean(axis=1), axis=0)
df_y_com = df_y.sub(df_y.mean(axis=1), axis=0)
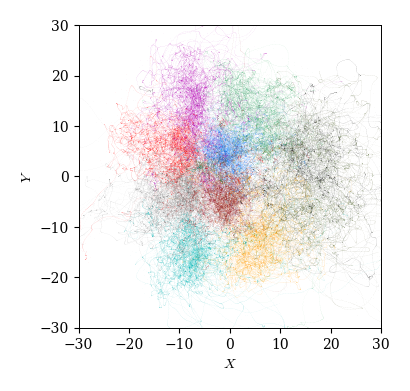
以下の2つのグラフは,いずれも重心座標系において全選手の位置を色分けしてプロットした結果である. 1つ目は選手ごとに各時刻の位置をマーカーでプロットしており,2つ目は選手ごとに平均位置と標準偏差を半径とする円をプロットしている.
fig, ax = plt.subplots(figsize=(4, 4))
for u in df_x.columns:
ax.plot(df_x_com[u], df_y_com[u], '.', ms=0.01)
ax.set_xlim(-30, 30); ax.set_ylim(-30, 30)
ax.set_aspect('equal')
ax.set_xlabel('$X$'); ax.set_ylabel('$Y$')
Text(0, 0.5, '$Y$')
fig, ax = plt.subplots(figsize=(4, 4))
cmap = plt.get_cmap("tab10") # カラーマップ
for i, u in enumerate(df_x.columns):
# 平均位置
ax.plot(df_x_com[u].mean(), df_y_com[u].mean(), 'x', ms=5, color=cmap(i))
# 標準偏差を半径とする円
r = np.sqrt(df_x_com[u].var() + df_y_mean[u].var())
theta=np.linspace(0, 2*np.pi)
ax.plot(df_x_com[u].mean()+r*np.cos(theta), df_y_com[u].mean()+r*np.sin(theta), '-', color=cmap(i))
ax.set_xlim(-30, 30); ax.set_ylim(-30, 30)
ax.set_aspect('equal')
ax.set_xlabel('$X$'); ax.set_ylabel('$Y$')
Text(0, 0.5, '$Y$')
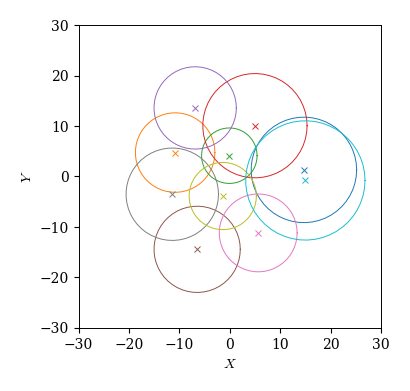
今度は選手ごとにだいたい決まった定位置(☓)を持ち,そこから標準偏差くらいの広がり(◯)を持つことが分かる. 特に,守備側から4人,4人,2人という並びになっており,おおよそ4-4-2というフォーメーションが見事に可視化されている.
7.4. アニメーション#
最後にトラッキングデータの解析の仕上げとして,アニメーションの作成方法を紹介する.
アニメーションはMatplotlibのFuncAnimationを用いると簡単に実装できる.
まずはFuncAnimationを以下のようにインポートしておく:
from matplotlib.animation import FuncAnimation
アニメーションを表示するには注意が必要である. これまで,MatplotlibによるグラフはJupyter上でインライン表示することができた. これは,デフォルトでグラフをインライン表示する設定になっているからであり,明示的に設定するには以下のコマンドを実行する:
%matplotlib inline
一方,アニメーションを表示するには,以下のコマンドを実行して,インライン表示ではなく別ウインドウで表示する設定に変更する必要がある.
%matplotlib tk
7.4.1. 位置#
# トラッキングデータの読み込み
df_x = pd.read_csv('./x_1st.csv', encoding='utf-8', index_col=0)
df_y = pd.read_csv('./y_1st.csv', encoding='utf-8', index_col=0)
# 描画関数
def update(i):
# 位置座標の更新
x, y = df_x.loc[int(i)], df_y.loc[int(i)]
pt.set_data(x, y)
return [pt]
# グラフの設定
fig, ax = plt.subplots(figsize=(5, 5))
pt, = ax.plot([], [], 'bo', ms=5, mfc='None')
ax.set_xlim(0, 105); ax.set_ylim(0, 68)
ax.set_xticks([0, 105]); ax.set_yticks([0, 68])
ax.set_aspect('equal')
# 実行
anim = FuncAnimation(fig, update, blit=True, interval=10)
7.4.2. 位置とテキスト#
# 描画関数
def update(i):
# 位置座標の更新
x, y = df_x.loc[int(i)], df_y.loc[int(i)]
pt.set_data(x, y)
# 時刻の表示
t = i*0.05
m, s = np.floor(t/60.).astype(int), np.floor(t % 60).astype(int)
ss = ("%.2f" % (t % 60 - s)).replace('.', '')[1:].zfill(2)
title.set_text(f"$t$={m}'{s}\"{ss}")
return list(np.hstack([pt, title]))
# グラフの設定
fig, ax = plt.subplots(figsize=(5, 5))
pt, = ax.plot([], [], 'bo', ms=5, mfc='None')
title = ax.text(80, 63, '', fontsize=10)
ax.set_xlim(0, 105); ax.set_ylim(0, 68)
ax.set_xticks([0, 105]); ax.set_yticks([0, 68])
ax.set_aspect('equal')
# 実行
anim = FuncAnimation(fig, update, blit=True, interval=10)
7.4.3. 位置・速度ベクトル・テキスト#
# 速度・速さの計算
df_vx = df_x.diff(20)
df_vy = df_y.diff(20)
df_v = np.sqrt(df_vx**2 + df_vy**2)
# 秩序変数の計算
df_op = np.sqrt(np.sum(df_vx/df_v, axis=1)**2 + np.sum(df_vy/df_v, axis=1)**2) / 10
# 描画関数
def update(i):
# 位置の更新
x, y = df_x.loc[int(i)], df_y.loc[int(i)]
pt.set_data(x, y)
# 速度ベクトルの更新
vx, vy = df_vx.loc[int(i)], df_vy.loc[int(i)]
arrow.set_offsets(np.c_[x, y])
arrow.set_UVC(vx, vy)
# 時刻の表示
t = i*0.05
m, s = np.floor(t/60.).astype(int), np.floor(t % 60).astype(int)
ss = ("%.2f" % (t % 60 - s)).replace('.', '')[1:].zfill(2)
text.set_text(f"$t$={m}\'{s}\"{ss} $\\phi$={df_op.loc[int(i)]:.2f}")
return list(np.hstack([pt, arrow, text]))
# グラフの設定
fig, ax = plt.subplots(figsize=(5, 5))
pt, = ax.plot([], [], 'bo', ms=5, mfc='None')
arrow = ax.quiver(np.zeros(10), np.zeros(10), np.zeros(10), np.zeros(10),\
color='b', angles='uv', units='xy', scale=0.7, width=0.5)
text = ax.text(65, 63, '', fontsize=10)
ax.set_xlim(0, 105); ax.set_ylim(0, 68)
ax.set_xticks([0, 105]); ax.set_yticks([0, 68])
ax.set_aspect('equal')
# 実行
anim = FuncAnimation(fig, update, blit=True, interval=20)